GPU 執行個體
Oracle Cloud Infrastructure (OCI) Compute 為裸機與虛擬機器 (VM) 執行個體提供業界領先的可擴充性與效能,並採用 NVIDIA 與 AMD GPU,支援主流圖形處理、AI 推論、AI 訓練、數位分身及高效能運算 (HPC)。

閱讀最新的 OCI 公告
-
NVIDIA Blackwell
瞭解 NVIDIA DGX Cloud 和 OCI 上 NVIDIA GB200 NVL72 系統的可用性。
-
Oracle 與 AMD 攜手合作
Oracle 與 AMD 宣布,AMD Instinct MI355X GPU 將可在 OCI 上使用,以支援大規模 AI 訓練與推論工作負載。
-
Seekr 選擇 OCI 作為可信賴的 AI 平台
Seekr 選用 OCI AI 基礎架構,以加速企業 AI 部署、多節點 AI 訓練及代理型 AI。
-
首要原則:Zettascale 超級叢集
瞭解 OCI 的叢集網路如何支援可擴展的生成式 AI。
-
主權 AI
Oracle 與 NVIDIA 提供全球主權 AI 解決方案
-
NVIDIA GPU 裝置外掛程式現已在 OCI Kubernetes Engine 上提供
OCI Kubernetes Engine 的外掛程式可提供更高的控制與彈性。
-
OCI AI Blueprints
輕鬆在生產環境中部署與擴展 AI 工作負載。
-
AMD Instinct MI300X GPU
搭載 AMD GPU 的 OCI Compute 裸機執行個體現已正式提供。
瞭解 Oracle AI 基礎架構與 AMD Instinct GPU 如何提供高效能、可擴展且具成本效益的 AI/ML 基礎。
為什麼 GPU 執行個體需要使用 OCI?
擴展性
131,072
OCI Supercluster 中的 GPU 數目上限 1
效能
3,200
高達 3,200 Gb/ 秒的 RDMA 叢集網路頻寬 2
價值
220%
其他 CSP 的 GPU 成本可能高出 220%3
多樣選擇
VM/BM
透過虛擬機器調整規模並透過裸機執行個體調整效能
1.OCI Supercluster 最多可擴展至 131,072 個 NVIDIA Blackwell B200 GPU;NVIDIA Grace Blackwell GB200 Superchips 中的 131,072 個 NVIDIA Blackwell B200 GPU;65,536 個 NVIDIA H200 Tensor Core GPU;32,768 個 NVIDIA A100 Tensor Core GPU;16,384 個 NVIDIA H100 Tensor Core GPU;以及 16,384 個 AMD MI300X GPU。
2. 適用於具有 NVIDIA B200、H200 和 H100 GPU 和 AMD Instinct MI300X 加速器的裸機執行個體。
3. 根據 2024 年 6 月 5 日的按需定價。
立即報名體驗 OCI Compute 服務的新「先試後買」計畫,使用 AMD Instinct MI300X GPU。
GPU 執行個體 - 主要功能
OCI 是唯一提供配備 NVIDIA 和 AMD GPU 的裸機執行個體的主要雲端供應商,以實現高效能且無需虛擬化開銷。對於 AI 訓練期間的檢查點,我們的執行個體為每個節點提供最大的本地儲存 (使用 H100 GPU 時為 61.4 TB)。
高效能 NVIDIA 和 AMD GPU
NVIDIA Tensor Core GPU
OCI 為裸機與虛擬機器運算執行個體提供超高價值與效能,支援 NVIDIA Blackwell GPU、H200 Tensor Core GPU、H100 Tensor Core GPU、L40S GPU、A100 Tensor Core GPU、A10 Tensor Core GPU 及早期型號的 NVIDIA GPU。
NVIDIA 超級晶片
OCI 提供 NVIDIA GB200 Grace Blackwell Superchip,其超級叢集可擴展至超過 10 萬個 GPU。
AMD Instinct 加速器
OCI 提供配備 192 GB 記憶體的 AMD Instinct MI300X GPU,售價極具競爭力,每 GPU 小時僅需 6 美元。
高效能叢集網路
Oracle 的超低延遲叢集網路是基於遠端直接記憶體存取 (RDMA),可達到微秒級低延遲。
在 VM、裸機執行個體和 Kubernetes 叢集上部署
VM 執行個體
對於虛擬機器,可以選擇 NVIDIA 的 Hopper、Ampere 和舊版 GPU 架構;每個虛擬機器具有一至四個核心、16 至 64 GB GPU 記憶體,以及高達 48 Gb/秒的網路頻寬。
裸機執行個體
使用搭載 AMD Instinct GPU、NVIDIA Blackwell GPU 或 Superchips、NVIDIA Hopper GPU 或 Superchips、NVIDIA Ampere GPU 的裸機執行個體。
Kubernetes 協調流程
利用託管 Kubernetes 、服務網格和容器登錄來協調 AI 和機器學習 (ML) 訓練和容器推論。
存取現成的軟體
存取軟體和磁碟映像
Oracle Cloud Marketplace 為資料科學、分析、人工智慧 (AI) 和機器學習 (ML) 模型提供軟體和磁碟映像,讓客戶能夠快速從資料中取得洞察分析。
NVIDIA AI Enterprise
存取 NVIDIA AI Enterprise,這是一個用於資料科學和生產 AI 的端對端軟體平台,其中包括生成式 AI、電腦視覺和語音 AI。
NVIDIA DGX Cloud
OCI 上的 NVIDIA DGX Cloud 是一個 AI 訓練即服務平台,為開發人員提供針對生成式 AI 進行最佳化的無伺服器體驗。
NVIDIA GPU Cloud Machine Image
使用 NVIDIA GPU Cloud Machine Image 存取數百個 GPU 最佳化的應用程式,以進行涵蓋各種產業和工作負載的機器學習、深度學習和高效能運算。
NVIDIA RTX Virtual Workstation
每當有需要時,員工可在 Oracle Cloud 上執行 NVIDIA RTX Virtual Workstation,以獲得強大的工作站效能。
控制您的 AI 運算環境和資料
OCI Dedicated Region
藉助 OCI Dedicated Region,在您的資料中心部署完整的雲端區域,以完全掌控您的資料和應用程式。
Oracle Alloy
成為 Oracle Alloy 的合作夥伴,提供雲端服務來滿足特定的市場需求。
微服務和容器
容器登錄
開發人員使用容器建置的應用程式,會利用 Oracle 管理的專用容器登錄服務來儲存和共用容器映像。使用 Docker V2 API 和標準 Docker 指令行介面 (CLI),將 Docker 映像推送至登錄或從中提取。映像可直接下載到 Kubernetes 部署位置。
Oracle 函數
函數即服務 (FaaS) 使開發人員能夠執行與 Oracle Cloud Infrastructure、Oracle Cloud Applications 和第三方服務整合的無伺服器應用程式。利用開源 Fn Project 社群來提高開發人員效率。
GPU 執行個體 - 使用案例
用於深度學習訓練和推論的 AI 基礎架構
使用 OCI Data Science、裸機執行個體、以 RDMA 為基礎的叢集網路和 NVIDIA GPU 訓練 AI 模型。
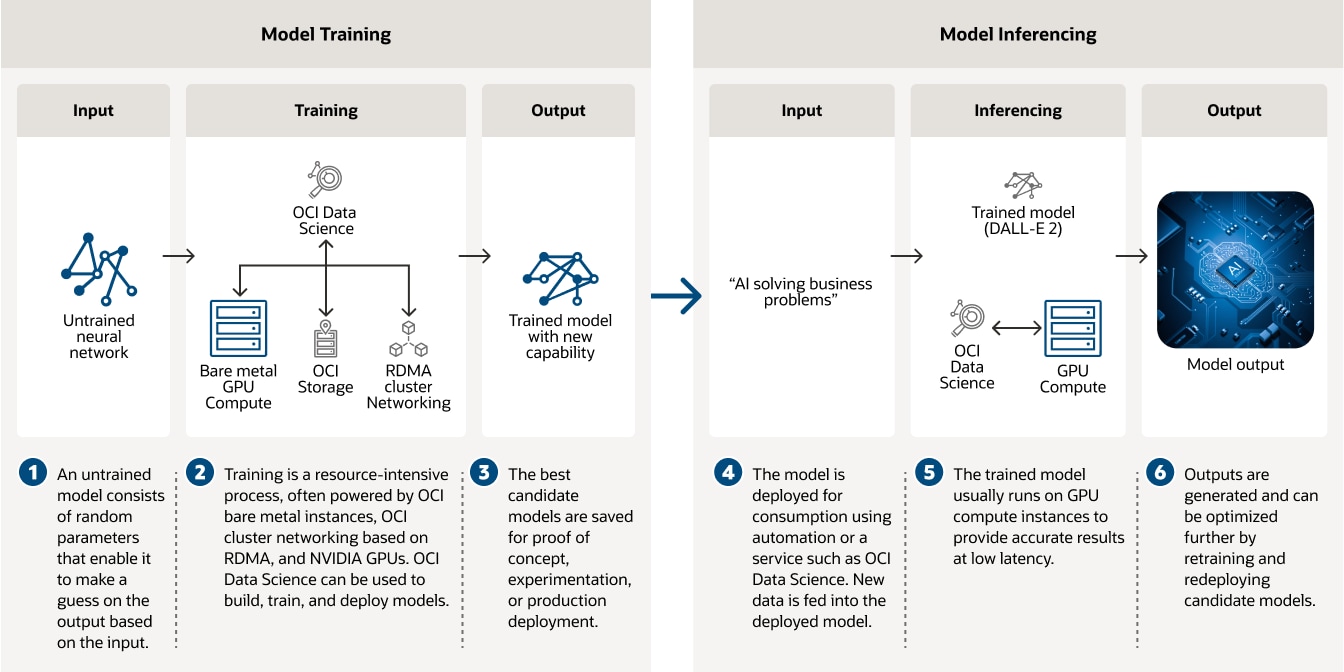 此圖表描述深度學習模型開發的兩個階段:模型訓練和模型推斷。在左側的模型訓練中,未訓練的神經網路會輸入至由 OCI 資料科學、裸機運算、本機儲存及叢集網路提供的訓練演算法。訓練演算法的輸出為具有新功能的訓練模型。右側描述模型推斷步驟。假設有一個訓練模型 (例如 DALL-E 2),可採用文字輸入並產生影像。文字輸入會饋送至訓練模型,然後從該模型提供影像輸出。
此圖表描述深度學習模型開發的兩個階段:模型訓練和模型推斷。在左側的模型訓練中,未訓練的神經網路會輸入至由 OCI 資料科學、裸機運算、本機儲存及叢集網路提供的訓練演算法。訓練演算法的輸出為具有新功能的訓練模型。右側描述模型推斷步驟。假設有一個訓練模型 (例如 DALL-E 2),可採用文字輸入並產生影像。文字輸入會饋送至訓練模型,然後從該模型提供影像輸出。
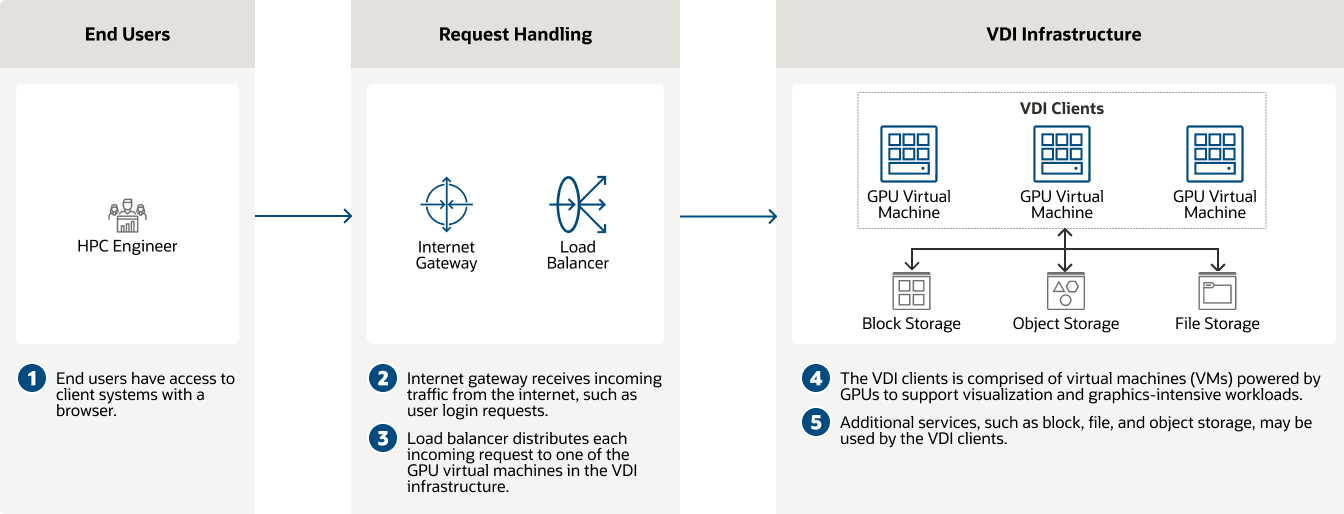
使用 GPU 執行個體進行 CFD 和高效能運算
OCI 啟用電腦輔助工程和運算流體動力學,以快速預測物體的空氣動力特性。
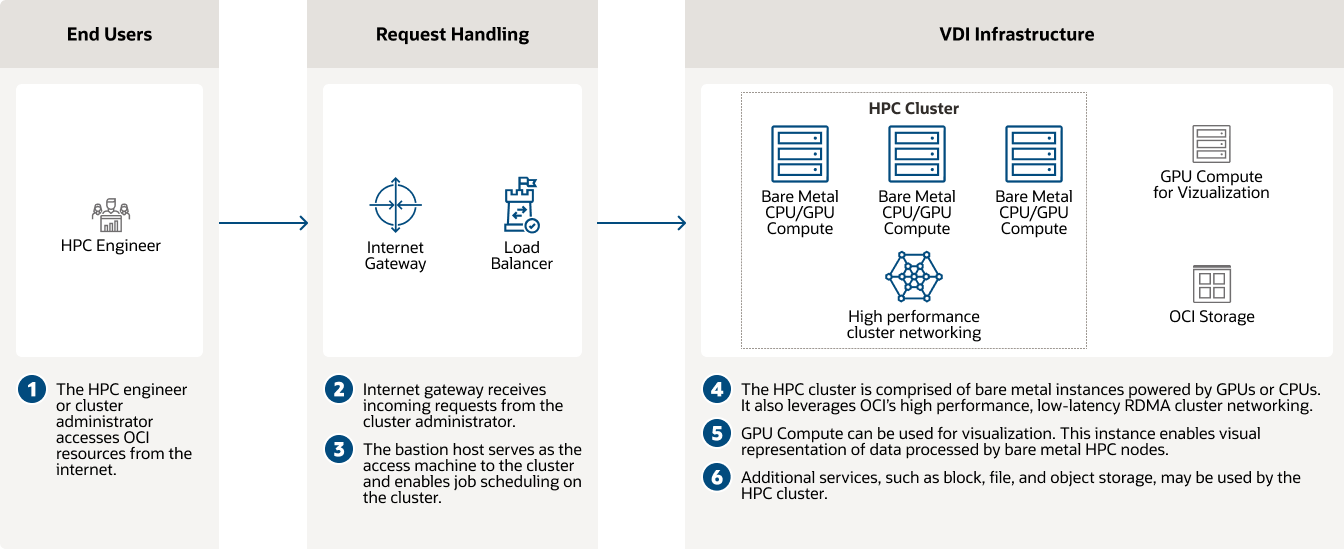 使用 GPU 執行個體進行 CFD 和高效能運算
使用 GPU 執行個體進行 CFD 和高效能運算
GPU 執行個體 — 客戶












開始使用 GPU 執行個體
試用 Oracle AI,並享有 30 天試用期
Oracle 針對大多數 AI 服務提供免費的定價等級,以及附贈 300 美元點數的免費試用帳戶,這些點數可用於試用額外的雲端服務。AI 服務是一系列具有預建機器學習模型的服務 (包括生成式 AI),可讓開發人員更輕鬆地將 AI 套用至應用程式和業務營運。
-
哪些 Oracle AI 和機器學習服務提供免費的定價等級?
- OCI Speech
- OCI Language
- OCI Vision
- OCI Document Understanding
- Oracle Database 中的機器學習功能
- OCI 資料標籤
您也只需要支付 OCI 資料科學的運算和儲存空間費用。
-
GPU 執行個體能做什麼?
- 托管基於 NVIDIA 和 AMD GPU 的大型語言模型 (LLM)
- 使用 NVIDIA GPU 執行分散式多節點訓練
- 使用 LLM 和檢索增強功能自動執行任務
- 擴展 NVIDIA NIM 推論
瞭解 OCI 可以助您節省多少成本
Oracle Cloud 的定價簡單明瞭,在全球各地保持一致的實惠價格,而且支援廣泛的使用案例。若要預估您的費率,請查看費用預估工具,並依照您的需要設定服務。
體驗與眾不同之處
- 1/4 的外送頻寬成本
- 3 倍運算性價比
- 每個區域的定價同樣實惠
- 定價實惠,且無須長期履行合約
-
我們的業務代表可以為您解答以下問題:
- 如何開始使用 Oracle Cloud?
- 我可以在 OCI 上執行哪些類型的 AI 工作負載?
- OCI 提供哪些類型的 AI 服務?