KI-Infrastruktur
Führen Sie selbst anspruchsvollste KI-Workloads schneller aus – darunter das Training und die Inferenz von Frontier-Modellen, agentenbasierte KI, wissenschaftliches Rechnen und Empfehlungssysteme – überall in unserer verteilten Cloud. Setzen Sie auf den Oracle Cloud Infrastructure (OCI) Supercluster mit bis zu 131.072 GPUs für Zettascale-Leistung.

Besuchen Sie Oracle auf der NVIDIA GTC
16. bis 19. März 2026
San Jose, CA und virtuell
-
![]() Entdecken Sie die KI-Trends, die Unternehmen im Jahr 2026 prägen werden
Entdecken Sie die KI-Trends, die Unternehmen im Jahr 2026 prägen werden
Nehmen Sie an unserer Webinarreihe teil und erfahren Sie, wie sich Ihre Organisation optimal vorbereitet.
-
![]() First Principles: Zettascale OCI Superclusters
First Principles: Zettascale OCI Superclusters
Die führenden Architekten von OCI zeigen, wie Clusternetzwerke skalierbare GenAI ermöglichen – von wenigen GPUs bis hin zu einem Zettascale-OCI-Supercluster mit 131.072 NVIDIA-Blackwell-GPUs.
![]() KI im Einsatz: 10 innovative Entwicklungen, die Sie jetzt kennenlernen sollten
KI im Einsatz: 10 innovative Entwicklungen, die Sie jetzt kennenlernen sollten
Entdecken Sie 10 bahnbrechende KI-gestützte Technologien, die die Art und Weise verändern, wie Unternehmen Wartung durchführen, mit Kunden interagieren, Daten schützen, Gesundheitsdienste bereitstellen und vieles mehr.
-
![]() Enterprise Strategy Group auf AMD Instinct MI300X
Enterprise Strategy Group auf AMD Instinct MI300X
Entdecken Sie die Einschätzung von Analysten zur OCI KI-Infrastruktur mit AMD-GPUs – und wie diese Kombination die Produktivität steigern, die Time-to-Value verkürzen und Energiekosten senken kann.




Co-Innovation von Oracle und NVIDIA
Erfahren Sie, wie die beiden Unternehmen die Einführung von KI beschleunigen.
Warum auf der OCI AI-Infrastruktur?

Leistung und Mehrwert
Verbessern Sie das KI-Training mit den einzigartigen GPU-Bare-Metal-Instanzen von OCI und dem ultraschnellen RDMA-Cluster-Netzwerk, das die Latenzzeit auf nur 2,5 Mikrosekunden reduziert. Sichern Sie sich attraktivere Preise für GPU-VMs.

HPC-Speicher
Nutzen Sie OCI File Storage mit High Performance Mount Targets (HPMTs) und Lustre, um Durchsatzraten von mehreren Terabyte pro Sekunde zu erreichen. Nutzen Sie bis zu 61,44 TB NVMe-Speicher – den höchsten Wert der Branche für GPU-Instanzen.

Souveräne KI
Mit der verteilten Cloud von Oracle können Sie KI-Infrastrukturen überall bereitstellen, um Leistungs-, Sicherheits- und Anforderungen an KI-Souveränität zu erfüllen. Erfahren Sie, wie Oracle und NVIDIA souveräne KI überall bereitstellen.
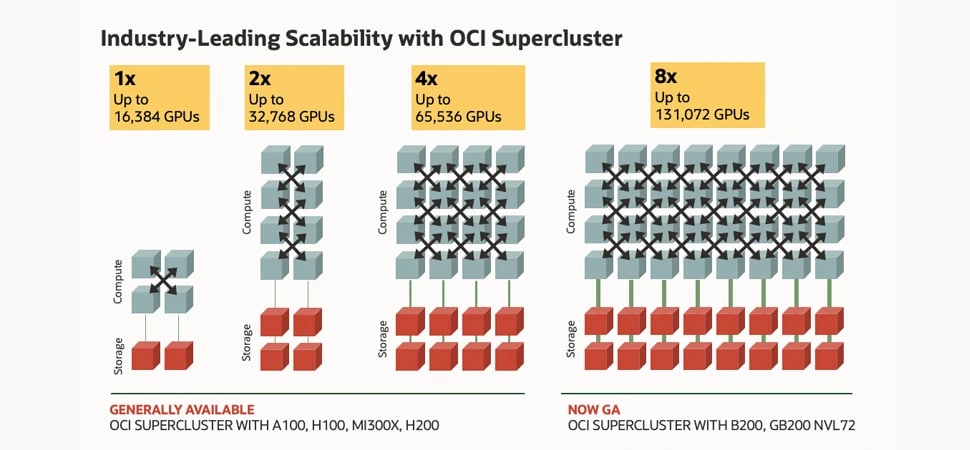 Das Bild zeigt Boxen, die für Rechenleistung und Speicherplatz stehen und durch Linien für Cluster-Netzwerke verbunden sind. Ganz links befinden sich vier Rechner- und zwei Speicherboxen für den kleinsten Cluster mit 16.000 NVIDIA H100-GPUs. Rechts davon befinden sich 8 Rechner- und 4 Lagerboxen für 32.000 NVIDIA A100-GPUs in einem Cluster. Als Nächstes folgen 16 Boxen mit Rechenleistung und 8 Boxen mit Speicherplatz für 64.000 NVIDIA H200-GPUs. Ganz rechts befinden sich schließlich 32 Rechner- und 16 Speicherboxen für 128.000 NVIDIA Blackwell- und Grace Blackwell-GPUs. Die Grafik verdeutlicht die Skalierbarkeit des OCI-Superclusters, die sich von der kleinsten Konfiguration mit 16.000 GPUs ganz links bis zur größten Konfiguration mit 128.000 GPUs ganz rechts um das Achtfache erhöht.
Das Bild zeigt Boxen, die für Rechenleistung und Speicherplatz stehen und durch Linien für Cluster-Netzwerke verbunden sind. Ganz links befinden sich vier Rechner- und zwei Speicherboxen für den kleinsten Cluster mit 16.000 NVIDIA H100-GPUs. Rechts davon befinden sich 8 Rechner- und 4 Lagerboxen für 32.000 NVIDIA A100-GPUs in einem Cluster. Als Nächstes folgen 16 Boxen mit Rechenleistung und 8 Boxen mit Speicherplatz für 64.000 NVIDIA H200-GPUs. Ganz rechts befinden sich schließlich 32 Rechner- und 16 Speicherboxen für 128.000 NVIDIA Blackwell- und Grace Blackwell-GPUs. Die Grafik verdeutlicht die Skalierbarkeit des OCI-Superclusters, die sich von der kleinsten Konfiguration mit 16.000 GPUs ganz links bis zur größten Konfiguration mit 128.000 GPUs ganz rechts um das Achtfache erhöht.
OCI-Supercluster mit NVIDIA Blackwell- und Hopper-GPUs
Bis zu 131.072 GPUs, 8-fache Skalierbarkeit
Innovationen im Netzwerk-Fabric ermöglichen es dem OCI Supercluster, auf bis zu 131.072 NVIDIA B200 GPUs zu skalieren – darunter über 100.000 Blackwell-GPUs in NVIDIA Grace Blackwell Superchips und 65.536 NVIDIA H200 GPUs.
OCI AI-Infrastruktur für alle Ihre Anforderungen
Ganz gleich, ob Sie Inferenzen oder Feinabstimmungen durchführen oder große Scale-Out-Modelle für generative KI trainieren möchten, OCI bietet branchenführende Bare Metal- und Virtual-Machine-GPU-Cluster-Optionen, die von einem Netzwerk mit extrem hoher Bandbreite und Hochleistungsspeicher unterstützt werden und Ihren KI-Anforderungen entsprechen.
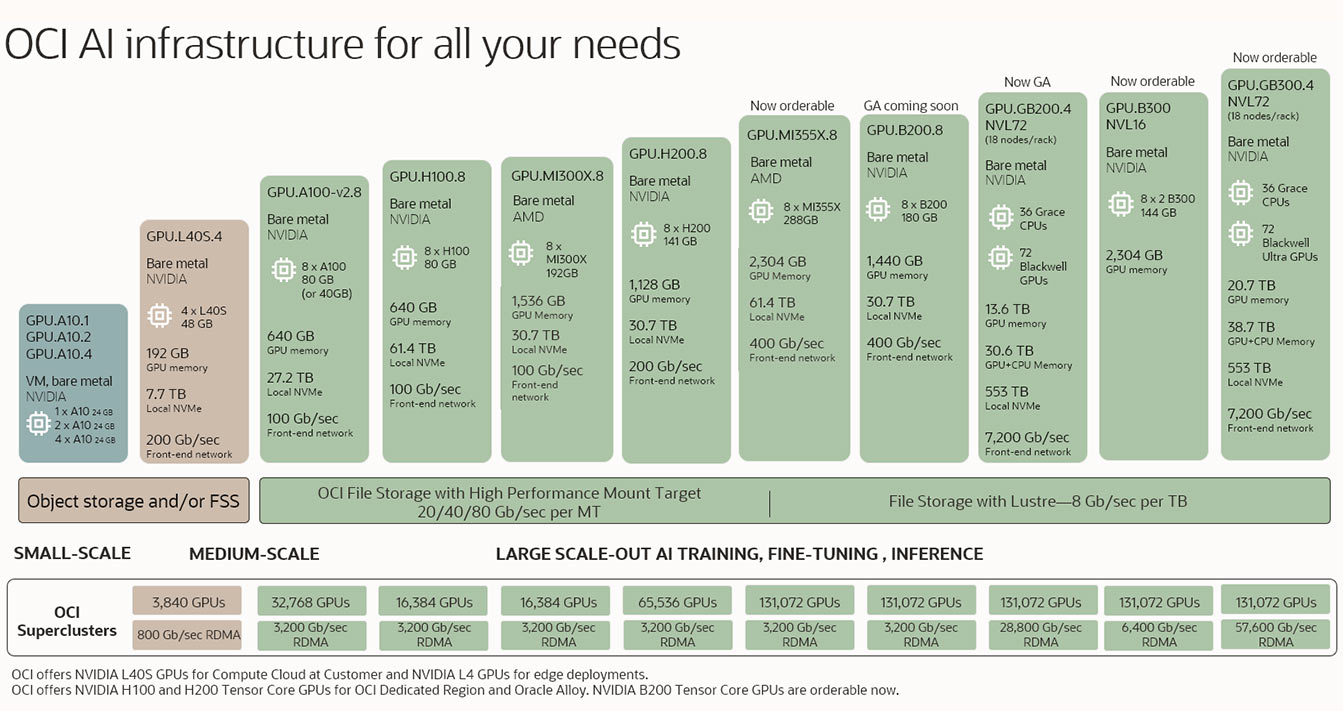 Das Bild zeigt mehrere Produkte für die KI-Infrastruktur, beginnend unten links mit den kleinsten Konfigurationen, die dann schrittweise zu Konfigurationen mittlerer und großer Größe ansteigen. Die kleinsten Konfigurationen bestehen aus nur 1 GPU in einer virtuellen Maschine und die größten Konfigurationen aus mehr als 100.000 GPUs in RDMA-Clustern.
Das Bild zeigt mehrere Produkte für die KI-Infrastruktur, beginnend unten links mit den kleinsten Konfigurationen, die dann schrittweise zu Konfigurationen mittlerer und großer Größe ansteigen. Die kleinsten Konfigurationen bestehen aus nur 1 GPU in einer virtuellen Maschine und die größten Konfigurationen aus mehr als 100.000 GPUs in RDMA-Clustern. Erfahren Sie am 11. Juni, wie Sie mit OCI und NVIDIA RTX PRO KI in der Produktion einsetzen können.
OCI Supercluster für KI-Training in großem Maßstab kennenlernen
Massive Scale-Out-Cluster mit NVIDIA Blackwell und Hopper
Leistungsstarkes Computing
• Bare-Metal-Instanzen ohne Hypervisor-Overhead
• Beschleunigt durch NVIDIA Blackwell (GB200 NVL72, HGX B200),
Hopper (H200, H100) und GPUs früherer Generationen
• Option zur Verwendung von AMD MI300X GPUs
• Datenverarbeitungseinheit (DPU) für integrierte Hardwarebeschleunigung
Speicher mit massiver Kapazität und hohem Durchsatz
• Lokaler Speicher: bis zu 61,44 TB NVMe-SSD-Kapazität
• Dateispeicher: Von Oracle verwalteter Dateispeicher mit Lustre und High Performance Mount Targets
• Blockspeicher: Balanced-, High-Performance- und Ultra-High-Performance-Volumes mit Performance-SLA
• Objektspeicher: verschiedene Speicherkategorien, Bucket-Replikation und hohe Kapazitätsgrenzen
Ultraschnelles Networking
• Maßgeschneidertes RDMA über Converged Ethernet-Protokoll (RoCE v2)
• 2,5 bis 9,1 Mikrosekunden Latenz für Cluster-Netzwerke
• Bis zu 3.200 Gb/s Cluster-Netzwerkbandbreite
• Bis zu 400 Gb/s Frontend-Netzwerkbandbreite
Compute für OCI Supercluster
Mit OCI-Bare-Metal-Instanzen auf Basis von NVIDIA GB200 NVL72, NVIDIA B200, NVIDIA H200, AMD MI300X, NVIDIA L40S, NVIDIA H100 und NVIDIA A100-GPUs können Sie große KI-Modelle für Anwendungsfälle ausführen, darunter Deep Learning, dialogorientierte KI und generative KI.
Mit OCI Supercluster können Sie pro Cluster auf mehr als 100.000 GB200 Superchips, 131.072 B200 GPUs, 65.536 H200 GPUs, 32.768 A100 GPUs, 16.384 H100 GPUs, 16.384 MI300X GPUs und 3.840 L40S GPUs skalieren.

Erweitern+
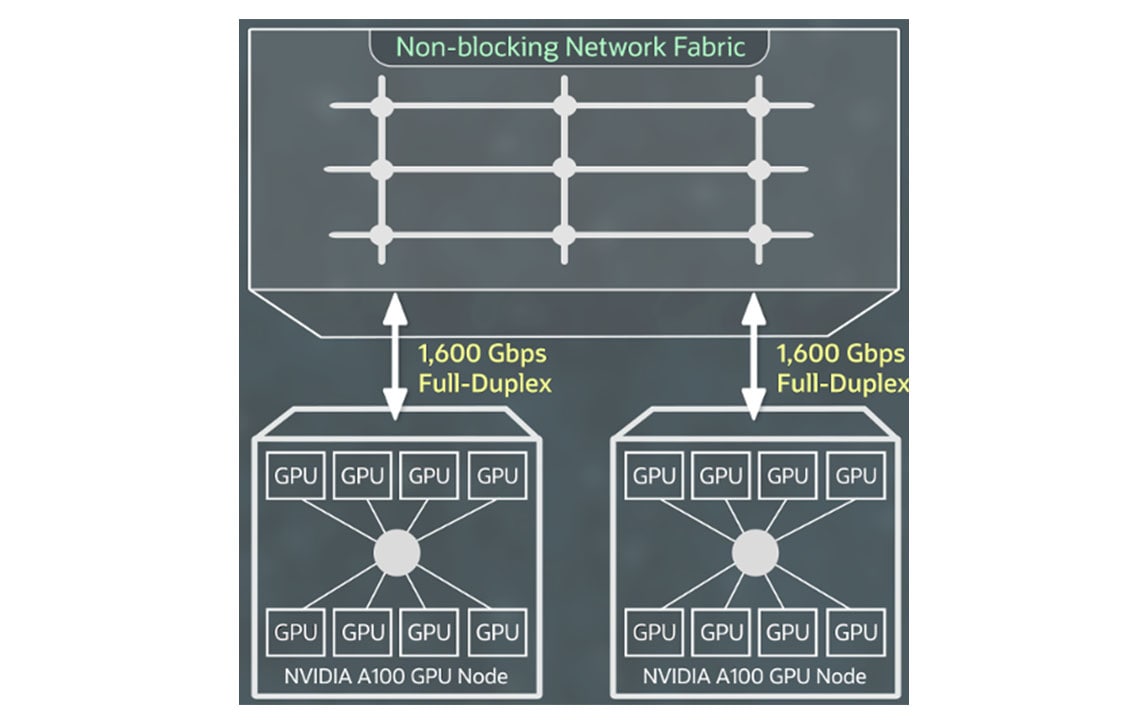
Networking für OCI Supercluster
Mit Hochgeschwindigkeits-RDMA-Cluster-Netzwerken, die von NVIDIA ConnectX-NICs mit RDMA über Converged Ethernet Version 2 angetrieben werden, können Sie große Cluster von GPU-Instanzen mit der gleichen extrem niedrigen Latenzzeit und Anwendungsskalierbarkeit erstellen, die Sie bei On-Premises erwarten.
Sie zahlen keinen Aufpreis für RDMA-Fähigkeit, Blockspeicher oder Netzwerkbandbreite und die ersten 10 TB Daten-Egress sind kostenlos.
Erweitern+
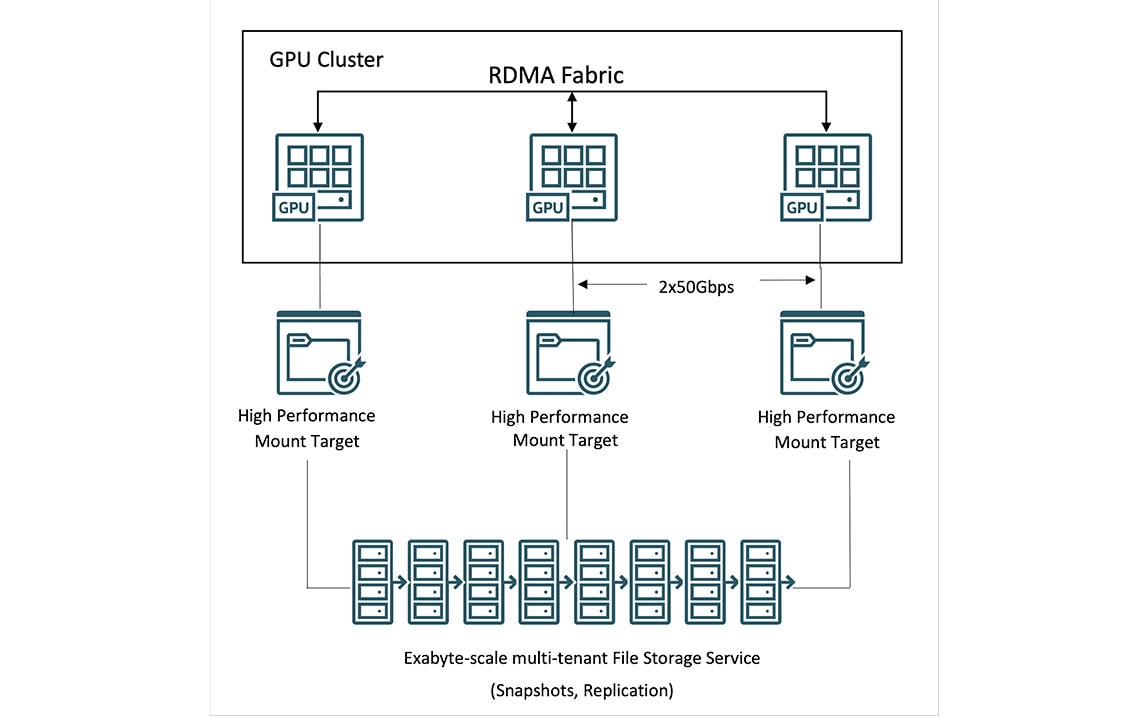
Storage für OCI Supercluster
Über OCI Supercluster können Kunden auf lokalen, Block-, Objekt- und Dateispeicher für Computing im Petabyte-Maßstab zugreifen. Unter den großen Cloud-Providern bietet OCI die größte Kapazität an lokalem NVMe-Hochleistungsspeicher für häufigeres Checkpointing während der Trainingsläufe, was zu einer schnelleren Wiederherstellung nach Ausfällen führt.
Für umfangreiche Datensätze bietet OCI leistungsstarken Dateispeicher mit Lustre und Mount Targets. HPC-Dateisysteme wie BeeGFS, GlusterFS und WEKA ermöglichen KI-Training in großem Maßstab – ohne Leistungseinbußen.

Zettascale OCI Superclusters
Sehen Sie, wie die führenden Architekten von OCI zeigen, wie Clusternetzwerke skalierbare generative KI ermöglichen. Von wenigen GPUs bis hin zu Zettascale-OCI-Superclustern mit über 131.000 NVIDIA-Blackwell-GPUs bieten Clusternetzwerke hohe Geschwindigkeit, geringe Latenz und ein resilientes Netzwerk für Ihre KI-Journey.
Seekr wählt Oracle Cloud Infrastructure, um vertrauenswürdige KI weltweit für Unternehmens- und Regierungskunden bereitzustellen
Abel Habtegeorgis, Oracle PRSeekr, ein auf vertrauenswürdige KI spezialisiertes Unternehmen, hat eine mehrjährige Vereinbarung mit Oracle Cloud Infrastructure (OCI) geschlossen, um den Einsatz von KI in Unternehmen deutlich zu beschleunigen und eine gemeinsame Go-to-Market-Strategie umzusetzen.
Vollständigen Beitrag lesenAusgewählte Blogs
- 26. März 2025 Ankündigung neuer KI-Infrastrukturfunktionen mit NVIDIA Blackwell für öffentliche, On-Premises- und Serviceprovider-Clouds
- 17. März 2025 Fortschritt der KI-Innovation: NVIDIA AI Enterprise und NVIDIA NIM auf OCI
- 17. März 2025 Oracle und NVIDIA liefern souveräne KI überall
- 11. März 2025 Von Zero zu AI Hero – Stellen Sie Ihre KI-Workloads schnell auf OCI bereit
Typische Anwendungsfälle für KI-Infrastrukturen
- Deep Learning-Training und Inferenzierung
- Betrugserkennung durch KI
- KI-gestützte medizinische Bildanalyse
- Einsatz von KI zur Beschleunigung der Arzneimittelforschung
Trainieren Sie KI-Modelle auf OCI Bare Metal-Instanzen, die von GPUs, RDMA-Cluster-Netzwerken und OCI Data Science unterstützt werden.

Der Schutz der Milliarden von Finanztransaktionen, die jeden Tag stattfinden, erfordert bessere KI-Tools, die große Mengen historischer Kundendaten analysieren können. KI-Modelle, die auf OCI Compute powered by NVIDIA GPUs zusammen mit Modellmanagement-Tools wie OCI Data Science und anderen Open-Source-Modellen laufen, helfen Finanzinstituten bei der Betrugsbekämpfung.

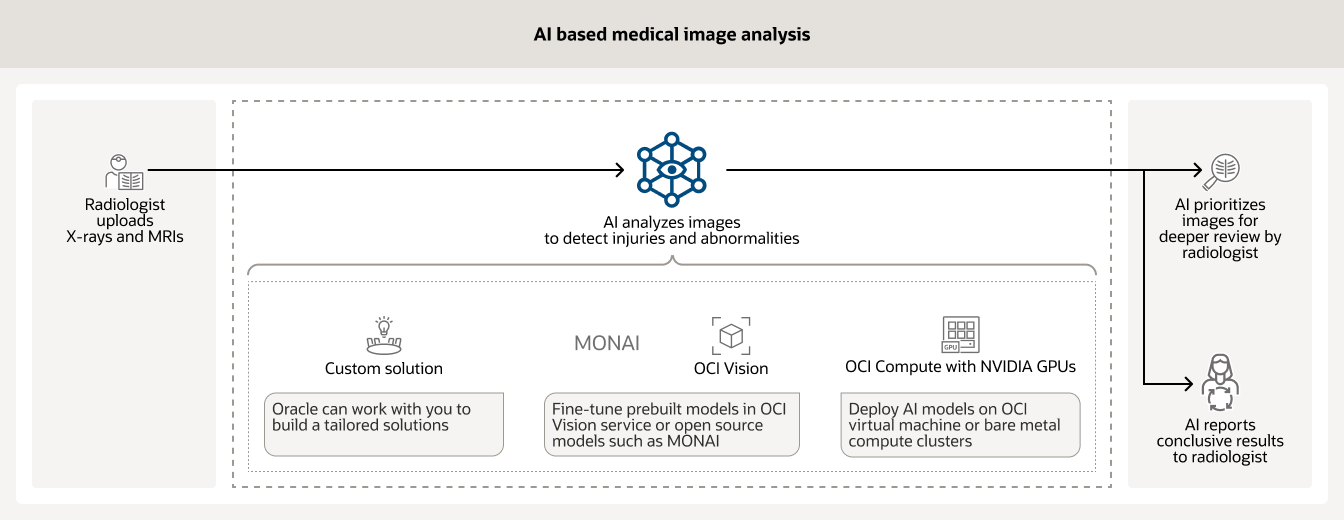
KI wird häufig zur Analyse verschiedener medizinischer Bilder (z. B. Röntgenbilder und MRTs) in Krankenhäusern eingesetzt. Trainierte Modelle können dabei helfen, Fälle zu priorisieren, die eine sofortige Überprüfung durch einen Radiologen erfordern, und aussagekräftige Ergebnisse für andere melden.
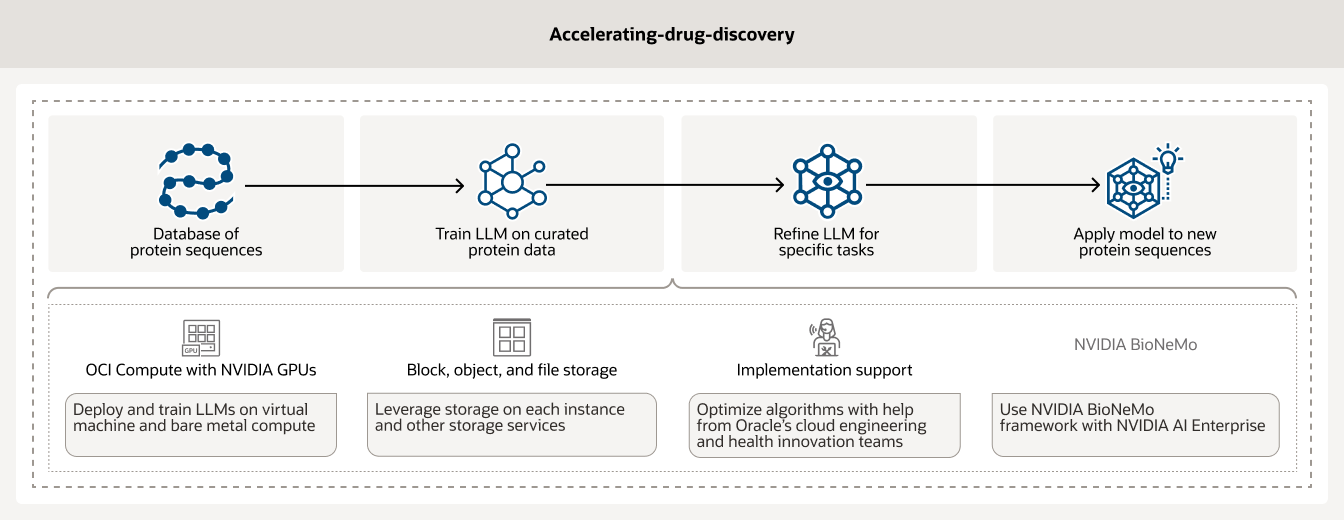
Die Entdeckung von Arzneimitteln ist ein zeitaufwendiger und teurer Prozess, der viele Jahre dauern und Millionen von Dollar kosten kann. Durch den Einsatz von KI-Infrastrukturen und -Analysen können Forscher die Arzneimittelentdeckung beschleunigen. Darüber hinaus ermöglicht OCI Compute powered by NVIDIA GPUs zusammen mit KI-Workflow-Management-Tools wie BioNeMo den Kunden, ihre Daten zu kuratieren und vorzuverarbeiten.
Kundenerfolge mit KI-Infrastrukturen















Erste Schritte mit der OCI KI-Infrastruktur
Zugriff auf KI-Subject Matter Experts (SMEs)
Holen Sie sich Hilfe beim Aufbau Ihrer nächsten KI-Lösung oder bei der Bereitstellung Ihrer Workloads auf der KI-Infrastruktur von OCI.
-
Sie können Fragen beantworten, z. B.
- Wie sehen die ersten Schritte in Oracle Cloud Infrastructure WAF aus?
- Welche Arten von KI-Workloads kann ich auf OCI ausführen?
- Welche Arten von KI-Services bietet OCI an?
Erfahren Sie, wie Sie KI noch heute anwenden können
Erleben Sie eine neue Ära der Produktivität mit generativen KI-Lösungen für Ihr Unternehmen. Erfahren Sie, wie Oracle seinen Kunden hilft, KI über den gesamten Technologiebereich hinweg zu nutzen.
-
Was Sie mit Oracle Cloud erreichen können
- Feinabstimmung von LLMs in OCI
- Automatisierung der Rechnungsverarbeitung
- Einen Chatbot mit RAG erstellen
- Web-Inhalte mit generativer KI zusammenfassen
- Und noch viel mehr!
Weitere Ressourcen
Erfahren Sie mehr über RDMA-Cluster-Networking, GPU-Instanzen, Bare Metal-Server und vieles mehr.
Erfahren Sie, welche Einsparungen mit OCI möglich sind.
Die Tarife für Oracle Cloud sind unkompliziert, mit weltweit konsequent niedrigen Tarifen und zahlreichen unterstützten Anwendungsfällen. Um den für Sie zutreffenden, niedrigen Tarif zu berechnen, gehen Sie zum Kostenrechner und konfigurieren Sie die Services entsprechend Ihrer Anforderungen.
Lernen Sie den Unterschied kennen:
- 1/4 der Kosten für ausgehende Bandbreite
- 3-mal besseres Preis-Leistungs-Verhältnis
- Gleicher niedriger Preis in jeder Region
- Niedrige Tarife ohne langfristige Verpflichtungen