Document Understanding 的特性
面向应用的人工智能模型
从文档扫描件、移动端上传文件、PDF 等文件中提取文本
OCI Document Understanding 采用光学字符识别 (OCR) 以及其他高级模型,可自动从各种文档文件(包括旋转、倾斜和有阴影的文档)中提取文本,有效解决费用处理和客户引导过程中常见的质量问题。
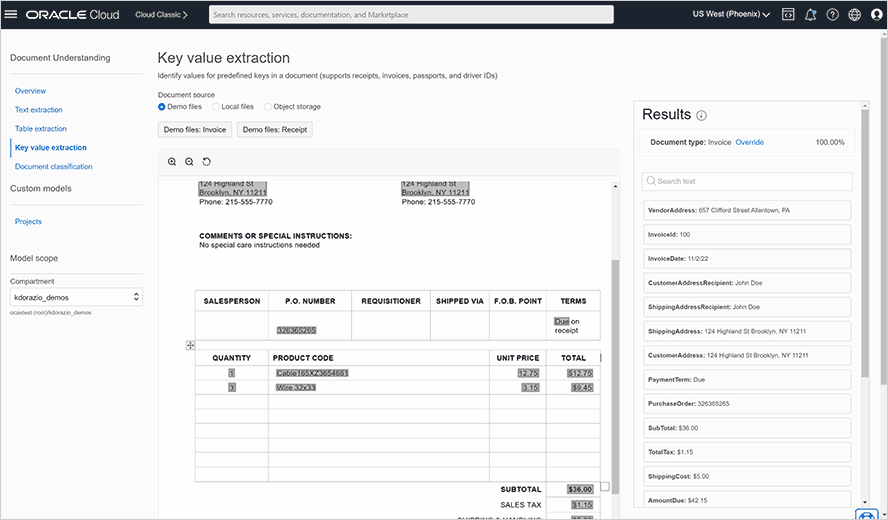
从文档中提取表格和关键字段
自动识别并提取文档中的表格结构,包括表格中的行和列关系。对于费用和身份文档,OCI Document Understanding 可以识别和提取发票、收据、护照、驾照和健康保险 ID 卡中的键值对。
文档分类
识别文档并将其分类到相应的通用类别中,例如发票、收据和简历。常见应用包括费用处理、增强文档搜索和检索。
多语言支持
OCI Document Understanding 面向光学字符识别和键值对的预训练模型支持多种语言,包括阿拉伯语、中文、荷兰语、英语、法语、德语、希伯来语、日语、葡萄牙语、俄语、西班牙语和乌克兰语。
自定义训练的模型
为键值对和文档分类使用场景创建自定义模型。借助 OCI Document Understanding,客户可以使用自有数据来训练、评估、部署和分析模型。
安全且易于访问
专为保护安全和隐私而打造
OCI Document Understanding 不在模型中存储任何训练、调试或其他数据,能够可靠保护客户隐私。
易于部署
OCI Document Understanding 功能完备,支持通过 REST API、SDK(包括 Python 和 Java)或 OCI 命令行调用。开发人员无需具备数据科学或机器学习的专业知识即可轻松部署可扩展的文档服务。
专用端点
通过供应专用端点来增强控制力,同时满足 OCI Document Understanding 工作流的高吞吐量要求。
注:为免疑义,本网页所用以下术语专指以下含义:
- 除Oracle隐私政策外,本网站中提及的“Oracle”专指Oracle境外公司而非甲骨文中国。
- 相关Cloud或云术语均指代Oracle境外公司提供的云技术或其解决方案。