Functies Document Understanding
AI-modellen die klaar zijn voor applicaties
Tekst extraheren uit gescande documenten, mobiele uploads, pdf's en meer
OCI Document Understanding maakt gebruik van optische tekenherkenning (Optical Character Recognition, OCR) en andere geavanceerde modellen om automatisch tekst uit allerlei documentbestanden te extraheren, waaronder documenten die zijn gedraaid of gekanteld, of documenten met schaduw, om kwaliteitsproblemen te voorkomen die vaak optreden bij de onkostenverwerking en onboarding van klanten.
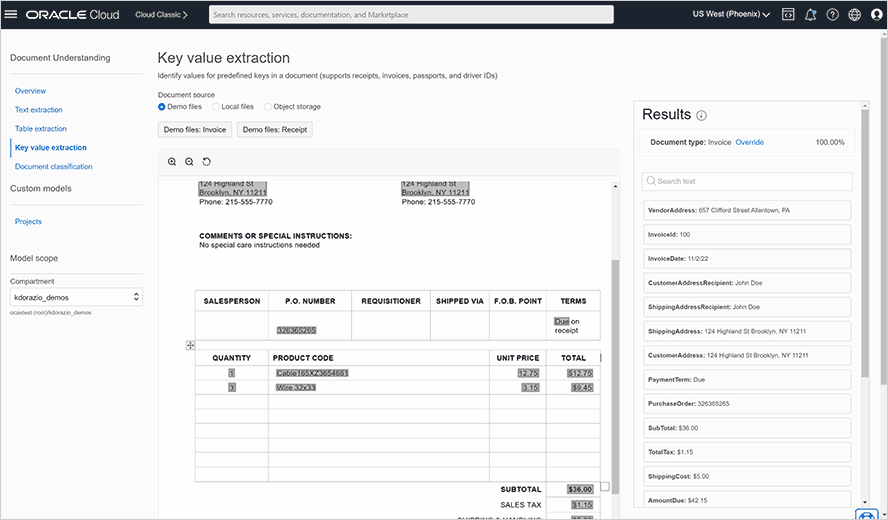
Tabellen en sleutelvelden extraheren uit documenten
Identificeer en extraheer automatisch tabelstructuren uit documenten, inclusief de rij- en kolomrelaties binnen de tabel. Voor onkosten- en identiteitsdocumenten kan OCI Document Understanding sleutelwaardeparen identificeren in en extraheren uit facturen, ontvangstbewijzen, paspoorten, rijbewijzen en ID-kaarten van ziektekostenverzekeringen.
Documenten categoriseren
Identificeer en classificeer documenten in algemene categorieën, zoals facturen, ontvangsten en cv's. Algemene applicaties omvatten onkostenverwerking en uitgebreid zoeken en ophalen van documenten.
Ondersteuning voor meerdere talen
De vooraf getrainde modellen voor optische tekenherkenning en sleutelwaardeparen van OCI Document Understanding ondersteunen meerdere talen, waaronder Arabisch, Chinees, Nederlands, Engels, Frans, Duits, Hebreeuws, Japans, Portugees, Russisch, Spaans en Oekraïens.
Op maat getrainde modellen
Maak aangepaste modellen voor sleutelwaardeparen en documentclassificatie. Met OCI Document Understanding kunnen klanten modellen trainen, evalueren, implementeren en analyseren met hun eigen gegevens.
Veilig en toegankelijk
Speciaal ontwikkeld voor veiligheid en privacy
OCI Document Understanding handhaaft privacy van de klant met modellen die geen gegevens opslaan voor training, foutenopsporing of andere doeleinden.
Eenvoudig te implementeren
OCI Document Understanding is een veelzijdige service die kan worden aangeroepen via REST-API's, meerdere SDK's (waaronder Python en Java) of de OCI-opdrachtregel. Ontwikkelaars kunnen eenvoudig een schaalbare documentservice implementeren zonder expertise te hebben op het gebied van datawetenschap of machine learning.
Dedicated eindpunten
Voorzie dedicated eindpunten voor meer controle en de mogelijkheid om te voldoen aan de vereisten voor een hoge doorvoer voor workflows van OCI Document Understanding.