Document Understanding 기능
바로 적용 가능한 애플리케이션용 AI 모델
문서 스캔본, 모바일 업로드 파일, PDF 등에서 텍스트를 추출합니다.
OCI Document Understanding은 비용 처리 및 고객 온보딩 과정에서 종종 발견되는 저품질 이미지 문제를 해결하고자 OCR(광학 문자 인식) 및 기타 고급 모델을 사용하여 회전, 기울기 또는 음영 처리된 문서를 포함한 다양한 문서 파일로부터 자동으로 텍스트를 추출합니다.
문서 내 테이블과 중요 필드 추출
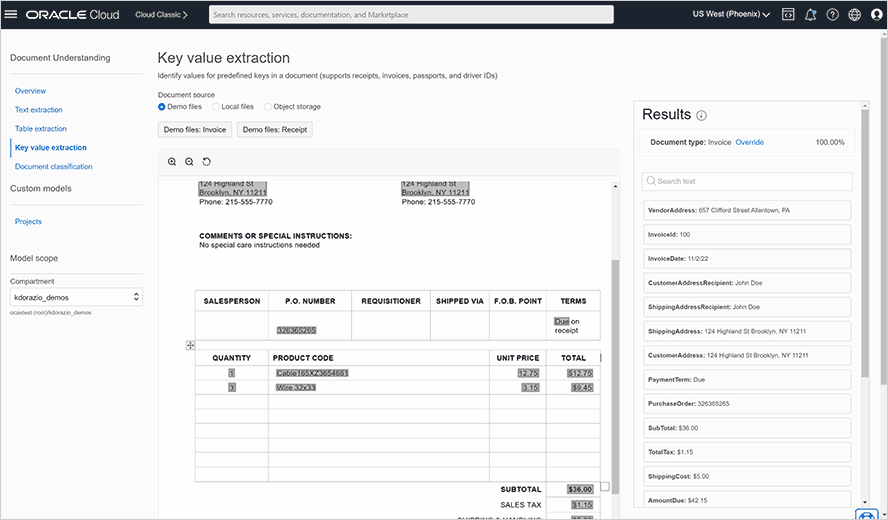
문서 내 테이블 구조를 행과 열 관계까지 포함하여 식별하고 추출할 수 있습니다. 비용 및 신원 문서의 경우 OCI Document Understanding은 송장, 영수증, 여권, 운전 면허증 및 건강 보험 ID 카드에서 키-값 쌍을 식별하고 추출할 수 있습니다.
문서 분류
문서를 송장, 영수증 및 이력서와 같은 공통 범주로 식별하고 분류해보세요. 일반적인 애플리케이션에는 경비 처리 및 고급 문서 조회 및 검색 기능이 포함됩니다.
다국어 지원
광학 문자 인식 및 키-값 쌍을 위한 OCI Document Understanding의 사전 학습 모델에서는 아랍어, 중국어, 네덜란드어, 영어, 프랑스어, 독일어, 히브리어, 일본어, 포르투갈어, 러시아어, 스페인어, 우크라이나어를 포함한 다양한 언어를 지원합니다.
맞춤형 지도 모델
키-값 쌍 및 문서를 분류하기 위한 커스텀 모델을 생성할 수 있습니다. 고객은 OCI Document Understanding을 사용하여 자체 데이터로 모델을 교육, 평가, 배포 및 분석할 수 있습니다.
보안 및 액세스
보안 및 개인정보 보호를 위한 맞춤 설계
OCI Document Understanding은 고객의 개인 정보를 보호하기 위해 훈련, 디버깅 또는 기타 목적으로 데이터를 저장하지 않는 모델을 사용합니다.
손쉬운 배포
OCI Document Understanding은 REST API, 다양한 SDK(Python 및 Java 포함) 또는 OCI 명령행을 통해 호출할 수 있어 활용도가 높은 서비스입니다. 데이터 과학이나 머신러닝 분야에 대한 전문성이 없는 개발자라도 확장 가능한 문서 서비스를 손쉽게 배포할 수 있습니다.
전용 엔드포인트
OCI Document Understanding 워크플로에 대한 높은 처리량 요구사항을 충족할 수 있도록 전용 엔드포인트를 프로비저닝할 수 있습니다.