GPUインスタンス
Oracle Cloud Infrastructure(OCI)Computeは、NVIDIAおよびAMD GPUを実装したベアメタルおよび仮想マシン(VM)インスタンスに業界をリードするスケーラビリティとパフォーマンスをもたらし、メインストリームのグラフィックス、AI推論、AIトレーニング、デジタルツイン、HPCを実現します。

OCIの最新の発表を読む
-
NVIDIA Blackwell
NVIDIA DGX CloudおよびOCI上のNVIDIA GB200 NVL72システムの可用性について詳細をご確認ください。
-
OracleとAMDのコラボレーション
オラクルとAMDは、大規模なAIトレーニングおよび推論ワークロードのために、AMD Instinct MI355X GPUがOCIで利用可能になることを発表しました。
-
Seekr、信頼できるAIのためにOCIを選択
Seekrは、OCIのAIインフラストラクチャを選択して、エンタープライズAIの導入、マルチノードAIトレーニング、エージェンティックAIを迅速化します。
-
第一原理: ゼタスケールのスーパークラスタ
OCIのクラスタ・ネットワークがスケーラブルな生成AIにどのように役立つかをご覧ください。
-
ソブリンAI
オラクルとNVIDIAは、ソブリンAIをどこでも提供します。
-
NVIDIA GPUデバイス・プラグイン用GA
OCI Kubernetes Engineのプラグインは、高度な制御と高い柔軟性を提供します。
-
OCI AI Blueprints
本番環境でのAIワークロードの導入と拡張が容易に行えます。
-
AMD Instinct MI300X GPU
AMD GPUを搭載したOCI Computeベアメタル・インスタンスの一般提供が開始されました。
6月11日、OCIとNVIDIA RTX PROを活用して本番環境のAIを強化する方法をご紹介します。
OCI for GPU instancesが使用される理由
拡張性
131,072
OCI Supercluster内のGPUの最大数1
パフォーマンス
3,200
最大3,200GbpsのRDMAクラスタ・ネットワーク帯域幅2
選択肢
VM/BM
ベアメタル・インスタンスによるVMでのサイズ適正化とパフォーマンス
1. OCI Superclusterは、最大131,072個のNVIDIA Blackwell B200 GPU、NVIDIA Grace Blackwell GB200 Superchip内で131,072のNVIDIA Blackwell B200 GPU、65,536個のNVIDIA H200 TensorコアGPU、32,768個のNVIDIA A100 TensorコアGPU、16,384個のNVIDIA H100 TensorコアGPU、および16,384個のAMD MI300X GPUまで拡張できます。
2. NVIDIA B200、H200、およびH100 GPUとAMD Instinct MI300Xアクセラレータを備えたベア・メタル・インスタンスの場合。
AMD Instinct MI300X GPUを搭載したOCIコンピュートの新しい購入前試用プログラムへのサインアップをお待ちしています。
GPUインスタンス—主な機能
OCIは、NVIDIAとAMD GPUを搭載したベアメタル・インスタンスを提供する唯一の大手クラウド・プロバイダーであり、仮想化のオーバーヘッドを伴わない高いパフォーマンスを実現します。AIトレーニング時のチェックポイント処理では、オラクルのインスタンスはノード当たりで最大のローカル・ストレージ(61.4TBとH100 GPU)を提供します。パフォーマンスと価格のバランスを考えると、NVIDIA GPUを搭載したOCI VMは、AWSやAzureよりも一貫して低価格です。
高パフォーマンスのNVIDIAおよびAMD GPU
NVIDIA TensorコアGPU
OCIは、NVIDIA Blackwell GPU、H200 TensorコアGPU、H100 TensorコアGPU、L40S GPU、A100 TensorコアGPU、A10 TensorコアGPU、および旧世代のNVIDIA GPUを実装したベアメタルおよび仮想マシン・コンピュート・インスタンスに最高の価値とパフォーマンスをもたらします。
NVIDIAスーパーチップ
OCIは、100,000を超えるGPUにまで拡張可能なスーパークラスタでNVIDIA GB200 Grace Blackwell Superchipを提供します。
AMD Instinctアクセラレータ
OCIは、192 GBのメモリを搭載したAMD Instinct MI300X GPUを、GPU時間あたり6ドルという魅力的な価格で提供します。
高パフォーマンスのクラスタ・ネットワーク
オラクルの超低レイテンシ・クラスタ・ネットワーキングは、リモート・ダイレクト・メモリ・アクセス(RDMA)をベースとし、マイクロ秒レベルのレイテンシを実現します。
VM、ベアメタル・インスタンス、Kubernetesクラスタに導入
VMインスタンス
VM向けには、NVIDIAのHopper、Ampere、および以前のGPUアーキテクチャから、1~4コア、VMあたり16~64 GBのGPUメモリ、および最大48 Gb/secのネットワーク帯域幅を選択できます。
ベアメタル・インスタンス
AMD Instinct GPU、NVIDIA Blackwell GPUまたはSuperchips、NVIDIA Hopper GPUまたは Superchips、NVIDIA Ampere GPUを含むベアメタル・インスタンスでOCI Superclusterを使用します。
Kubernetesによるオーケストレーション
マネージドKubernetes、サービス・メッシュ、コンテナ・レジストリを活用し、コンテナを使用してAIおよび機械学習(ML)のトレーニングや推論をオーケストレーションします。
すぐに利用可能なソフトウェアにアクセス
ソフトウェアおよびディスク・イメージへのアクセス
Oracle Cloud Marketplaceでは、データ・サイエンス、分析、人工知能(AI)、および機械学習(ML)モデル用のソフトウェアとディスク・イメージを提供します。これにより、お客様はデータから迅速にインサイトを得ることができます。
NVIDIA AI Enterprise
NVIDIA AI Enterpriseへのアクセスを取得しましょう。これは、生成AI、コンピュータ・ビジョン、音声AIといったデータ・サイエンスおよび本番AI向けの、エンドツーエンドのソフトウェア・プラットフォームです。
NVIDIA DGX Cloud
OCI上のNVIDIA DGX Cloudは、サービスとしてのAIトレーニングを提供するプラットフォームであり、生成AI向けに最適化されたサーバーレス環境を開発者に提供します。
NVIDIA GPU Cloud Machine Image
NVIDIA GPU Cloud Machine Imageを使用すると、幅広い業界やワークロードに対応する、機械学習、ディープラーニング、ハイパフォーマンス・コンピューティング向けにGPU最適化された数百のアプリケーションを利用できます。
NVIDIA RTX仮想ワークステーション
Oracle Cloud上でNVIDIA RTX仮想ワークステーションを実行することにより、従業員が必要とするあらゆる場所で強力なワークステーション・パフォーマンスを実現できます。
AIコンピューティングの環境とデータを制御
分散クラウド
OCIの分散クラウドは、GPUのコンピュートと組み合わせることで、AIとクラウド・サービスをどの場所で、どのような方法で実行するかを制御できます。
ソブリン・クラウド
EU、米国、英国、オーストラリアなどの地域内や国内におけるデータ・レジデンシーに対応します。
OCIの専用リージョン
OCI Dedicated Regionでフル機能のクラウド・リージョンをデータセンターに導入すると、データとアプリケーションを詳細に制御できます。
Oracle Alloy
Oracle Alloyのパートナーになると、市場の特定のニーズに応えるクラウド・サービスを提供できます。
マイクロサービスとコンテナ
コンテナ・レジストリ
コンテナを使用してアプリケーションを構築する開発者は、オラクルが管理する可用性の高いプライベート・コンテナ・レジストリ・サービスを活用して、コンテナ・イメージを保存および共有できます。Docker V2 APIおよび標準のDockerコマンド・ライン・インターフェイス(CLI)を使用して、レジストリとの間でDockerイメージをプッシュまたはプルします。イメージをKubernetesデプロイメントに直接プルできます。
Oracle Functions
Functions as a Service(FaaS)を使用すると、開発者はOracle Cloud Infrastructure、Oracle Cloud Applications、およびサードパーティのサービスと統合されるサーバーレス・アプリケーションを実行できます。オープン・ソースFnプロジェクトのコミュニティとともに開発者の効率を改善します。
GPUインスタンス—ユースケース
ディープラーニングのトレーニングや推論のためのAIインフラストラクチャ
OCI Data Scienceや、ベアメタル・インスタンス、RDMAに基づくクラスタ・ネットワーキング、およびNVIDIA GPUを使用して、AIモデルのトレーニングを行います。
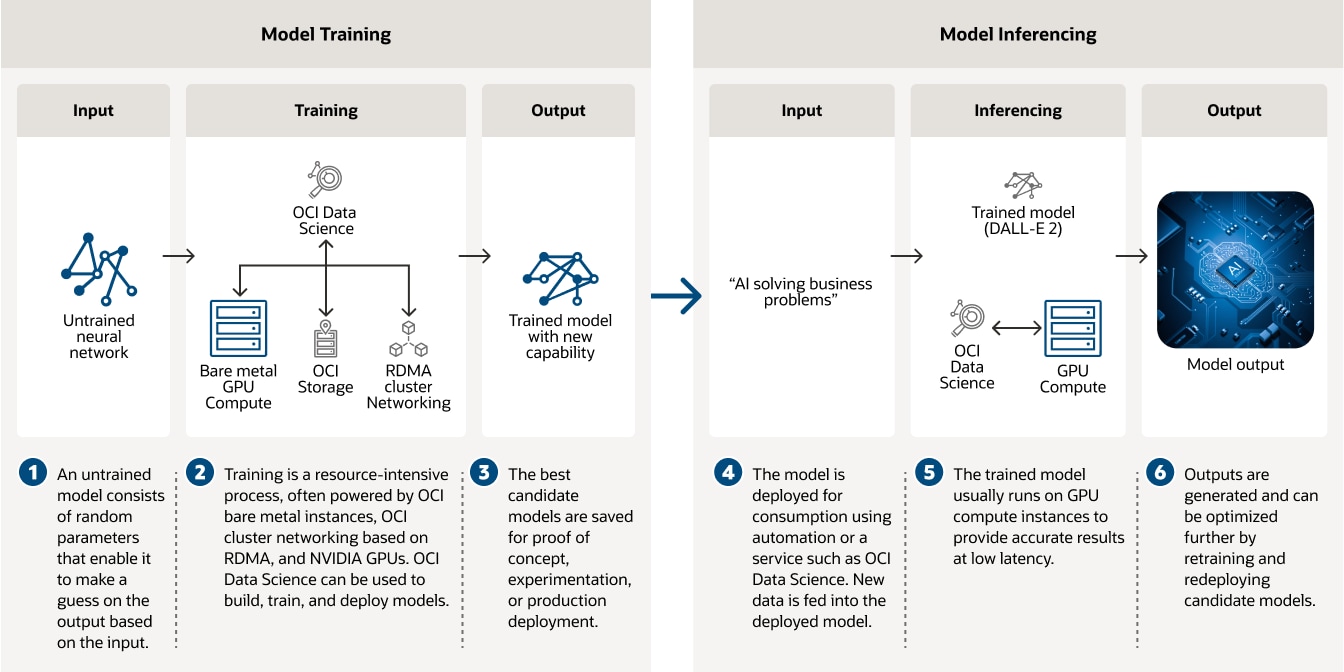 この図は、ディープラーニングのモデル開発における2つの段階である、モデルトレーニングとモデル推論について説明するものです。左側のモデルトレーニングでは、OCI Data Scienceやベアメタル・コンピュート、ローカルストレージ、およびクラスタ・ネットワーキングなどで実行されるトレーニング・アルゴリズムに、未トレーニングのニューラル・ネットワークが入力されます。新しい能力を持つトレーニング済みモデルが、トレーニング・アルゴリズムから出力されます。モデルの推論ステップは、右側に説明されています。DALL-E 2のような、テキスト入力を受けて画像を生成することができるトレーニング済みモデルを考えてみましょう。テキスト入力がとトレーニング済みモデルに供給され、モデルから画像が出力されます。
この図は、ディープラーニングのモデル開発における2つの段階である、モデルトレーニングとモデル推論について説明するものです。左側のモデルトレーニングでは、OCI Data Scienceやベアメタル・コンピュート、ローカルストレージ、およびクラスタ・ネットワーキングなどで実行されるトレーニング・アルゴリズムに、未トレーニングのニューラル・ネットワークが入力されます。新しい能力を持つトレーニング済みモデルが、トレーニング・アルゴリズムから出力されます。モデルの推論ステップは、右側に説明されています。DALL-E 2のような、テキスト入力を受けて画像を生成することができるトレーニング済みモデルを考えてみましょう。テキスト入力がとトレーニング済みモデルに供給され、モデルから画像が出力されます。
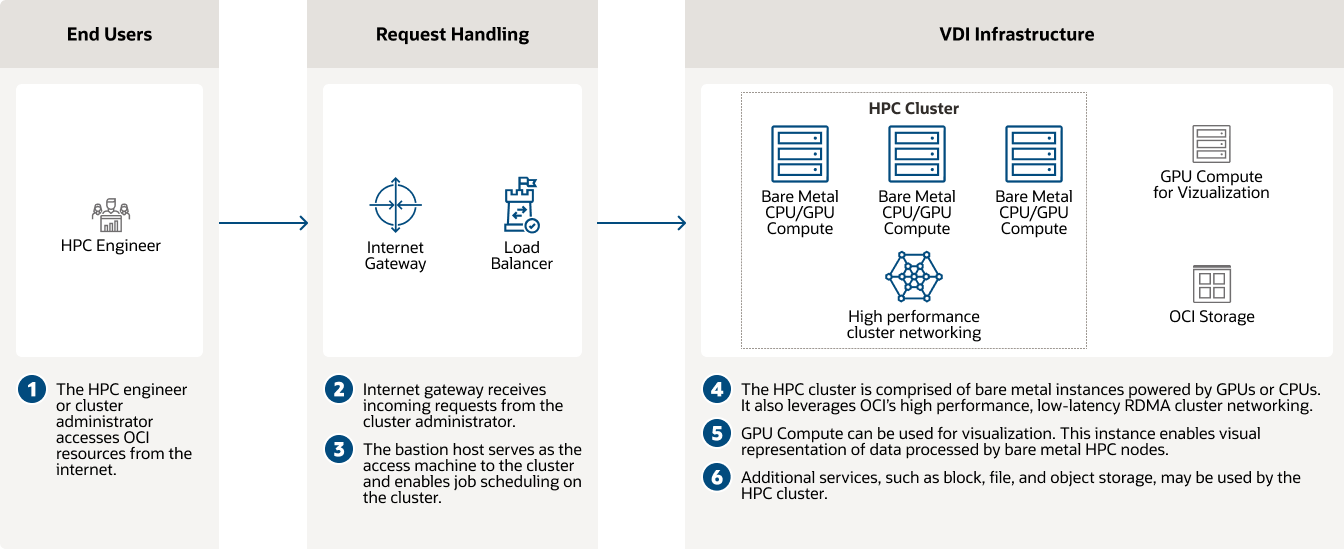
仮想デスクトップ・インフラストラクチャ(VDI)
NVIDIA GPUを活用したOCI Computeは、VDIに対して一貫した高パフォーマンスを提供します。
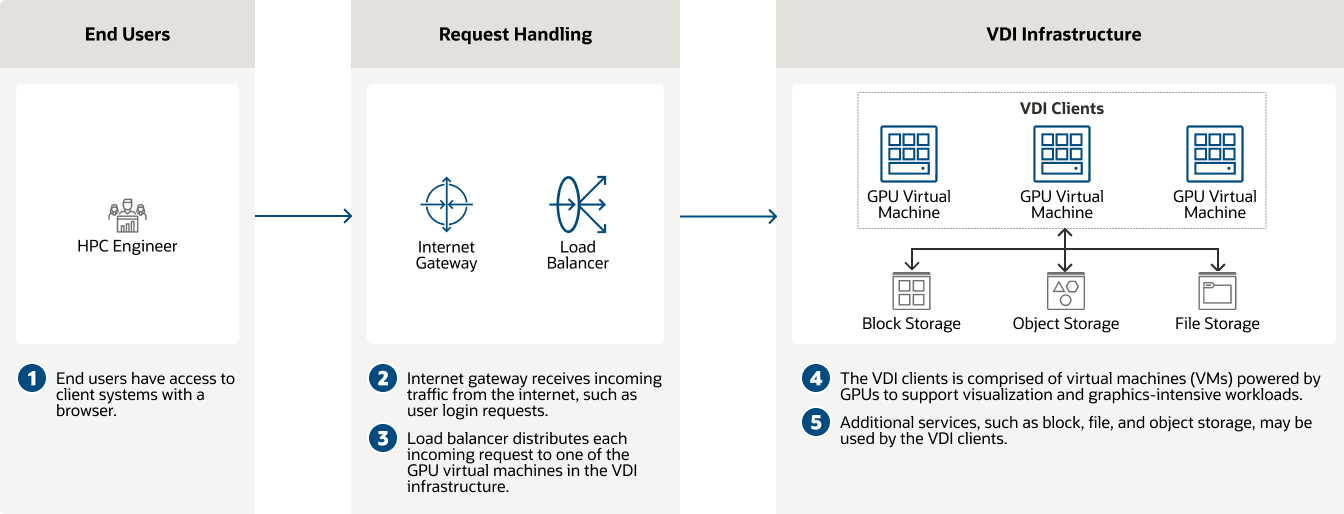 仮想デスクトップ・インフラストラクチャ
仮想デスクトップ・インフラストラクチャ
GPUインスタンスを使用したCFDと高パフォーマンス・コンピューティング
OCIは、物体の空力特性を迅速に予測するためのコンピュータ支援エンジニアリングと計算流体力学を実現します。
 GPUインスタンスを使用したCFDと高パフォーマンス・コンピューティング
GPUインスタンスを使用したCFDと高パフォーマンス・コンピューティング
GPUインスタンス—お客様












GPUインスタンスの利用を始める
Oracle AIを30日間試してみる
オラクルでは、ほとんどのAIサービスで無料価格帯を提供しています。また、無料トライアル・アカウントに提供されるUS$300のクレジットを使って、追加のクラウド・サービスをお試しいただけます。AIサービスとは、開発者がアプリケーションや業務にAIを簡単に適用できるようにする、デフォルトの機械学習モデルを備えた生成AIなどを含む一連のサービスです。
-
Oracle AIおよびMLサービスのうち、無料価格帯を提供しているもの
- OCI Speech
- OCI Language
- OCI Vision
- OCI Document Understanding
- Machine Learning in Oracle Database
- OCI Data Labeling
また、OCI Data Scienceではコンピュートとストレージの使用料のみ。
-
GPUインスタンスで実現できること
- NVIDIAおよびAMDのGPUを使用してLLMをホスティング
- NVIDIA GPUを使用して分散マルチノード・トレーニングを実行
- LLMと検索拡張生成を使用してタスクを自動化
- NVIDIA NIM推論をスケーリング
OCIでのコスト削減を試算してみましょう
Oracle Cloudの価格は、わかりやすく、世界中で一貫性のある低価格であり、さまざまなお客様事例をサポートしています。コストを見積もるには、コスト見積ツールをチェックし、ニーズに応じて、サービスを設定します。
違いを体験してください
- 1/4のアウトバウンド帯域幅コスト
- コンピューティングのコストパフォーマンスが3倍向上
- すべてのリージョンで同じ低価格
- 長期のコミットメントなしの低価格
GPUおよびAIのエキスパートにアクセス
次期AIソリューションの構築やOCI AIインフラストラクチャへのAIワークロードの導入をお手伝いするサポートをご利用ください。
-
次のような質問に回答できます。
- Oracle Cloudを使い始めるには、どうすればよいですか?
- OCIで実行可能なAIワークロードを教えてください。
- OCIで提供されているAIサービスを教えてください。