概要
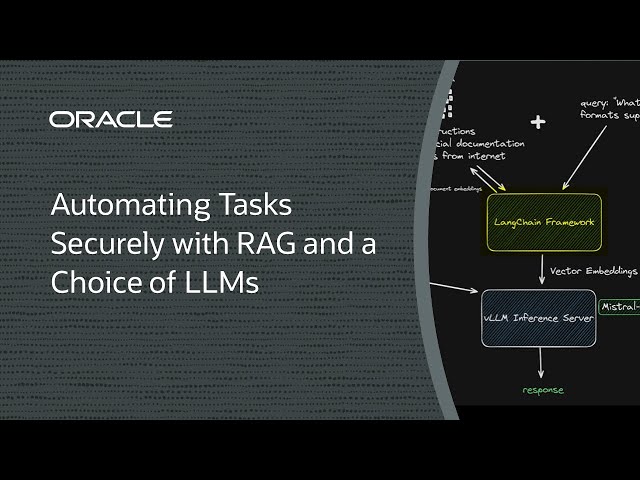
反復的なタスクを合理化したり、完全に自動化するために、AIの助けを借りないのはなぜですか? 基盤モデルを使用して反復的なタスクを自動化すると、魅力的になる可能性がありますが、機密データが危険にさらされる可能性があります。取得拡張生成(RAG)はファインチューニングの代替手段であり、推論データをモデルのコーパスから分離したままにします。
推論データとモデルを分離したままにしたいのですが、大規模言語モデル(LLM)と強力なGPUを使用して効率性を確保することもできます。これだけのGPUがあればいいのに!
このデモでは、単一のNVIDIA A10 GPU、LangChain、LlamaIndex、Qdrant、vLLMなどのオープン・ソース・フレームワーク、およびMistral AIからの70億パラメータLLMを使用してRAGソリューションをデプロイする方法を示します。これは、価格とパフォーマンスの優れたバランスであり、必要に応じてデータを更新しながら推論データを分離します。
デモ