AIインフラストラクチャ
フロンティア・モデルのトレーニングと推論、エージェント型AI、科学的コンピューティング、レコメンデーション・エンジンなど、最も要求の厳しいAIワークロードを分散クラウドのあらゆる場所で高速に実行できます。Oracle Cloud Infrastructure(OCI)Superclusterを使用して、zettascaleでのパフォーマンスを最大131,072 GPUにします。

NVIDIA GTCでオラクルに参加
2026年3月16日~19日
カリフォルニア州サンノゼおよびバーチャル
-
![]() 2026年にビジネスへ影響を与えるAIトレンドをご紹介します
2026年にビジネスへ影響を与えるAIトレンドをご紹介します
このウェビナーシリーズでは、組織としてどのように備えるべきかを学ぶことができます。
-
![]() 第一の原則: Zettascale OCI Superclusters
第一の原則: Zettascale OCI Superclusters
数台のGPUから131,072個のNVIDIA Blackwell GPUを搭載した大規模なOCI Superclusterまで、クラスタ・ネットワークがスケーラブルな生AIを支える仕組みを、OCIのトップ・アーキテクトが説明します。
![]() AI活用の最前線: 今すぐチェックすべき10の最新イノベーション
AI活用の最前線: 今すぐチェックすべき10の最新イノベーション
メンテナンス、カスタマー・エンゲージメント、データ・セキュリティ、医療など、組織のあり方を変えるAIによる10の画期的なテクノロジーをご覧ください。
-
![]() AMD Instinct MI300Xに関するEnterprise Strategy Group
AMD Instinct MI300Xに関するEnterprise Strategy Group
AMD GPUを搭載したOCI AIインフラと、この組み合わせによる生産性の向上、価値実現までの時間の短縮、エネルギー・コストの削減方法に関するアナリストの見解をご覧ください。




OracleとNVIDIAの共同イノベーション
両企業がAI導入を加速させる方法をご覧ください。
OCI AIインフラストラクチャで実行する理由

パフォーマンスと価値
OCI独自のGPUベアメタル・インスタンスと超高速RDMAクラスタ・ネットワーキングにより、レイテンシをわずか2.5マイクロ秒に短縮し、AIトレーニングを強化します。GPU VMのお得な価格をぜひご確認ください。

HPCストレージ
Leverage OCI File Storage with 高パフォーマンス・マウント・ターゲット (HPMTs)およびLustre を備えた OCI ファイル ストレージを活用して、毎秒テラバイトのスループットを実現します。GPUインスタンスで業界最高の最大61.44 TBのNVMeストレージを使用します。

ソブリンAI
オラクルの分散クラウドでは、AIインフラストラクチャをどこにでも導入可能になるため、パフォーマンス、セキュリティ、AI主権の要件を満たせるよう支援します。OracleとNVIDIAがソブリンAIをどこにでも提供する方法をご覧ください。
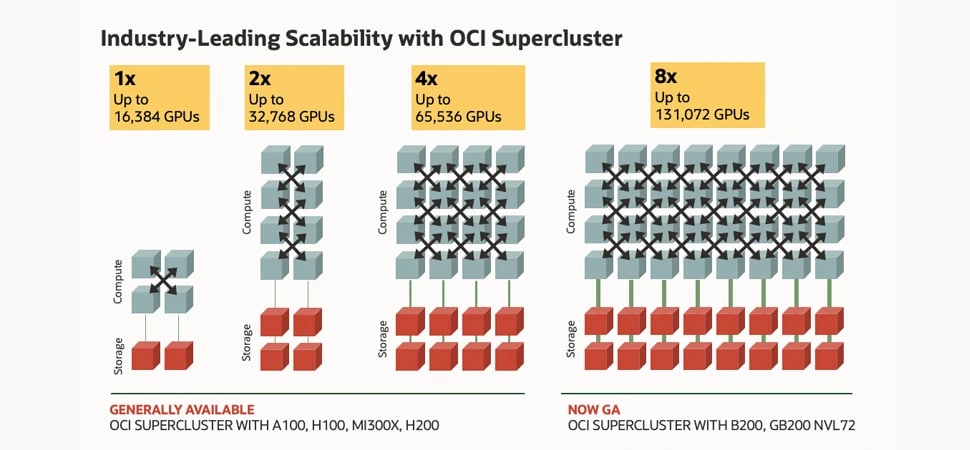 この図では、コンピュートとストレージを表すボックスが、クラスタ・ネットワークの線で結ばれています。左端には、16,000個のNVIDIA H100 GPUを搭載した最小クラスタ用の4個のコンピュートボックスと、2個のストレージボックスがあります。その右側には、32,000個のNVIDIA A100 GPUを搭載したクラスタ用の8個のコンピュートボックスと、4個のストレージボックスがあります。その隣には、64,000個のNVIDIA H200 GPU用の16個のコンピュートボックスと8個のストレージボックスがあります。最後に、右端には、128,000個のNVIDIA BlackwellおよびGrace Blackwell GPU用の32個のコンピュートボックスと16個のストレージボックスがあります。これは、左端の最小構成である16,000個のGPUから右端の最大構成である128,000個のGPUまで、8倍に拡張できるOCI Superclusterのスケーラビリティを示しています。
この図では、コンピュートとストレージを表すボックスが、クラスタ・ネットワークの線で結ばれています。左端には、16,000個のNVIDIA H100 GPUを搭載した最小クラスタ用の4個のコンピュートボックスと、2個のストレージボックスがあります。その右側には、32,000個のNVIDIA A100 GPUを搭載したクラスタ用の8個のコンピュートボックスと、4個のストレージボックスがあります。その隣には、64,000個のNVIDIA H200 GPU用の16個のコンピュートボックスと8個のストレージボックスがあります。最後に、右端には、128,000個のNVIDIA BlackwellおよびGrace Blackwell GPU用の32個のコンピュートボックスと16個のストレージボックスがあります。これは、左端の最小構成である16,000個のGPUから右端の最大構成である128,000個のGPUまで、8倍に拡張できるOCI Superclusterのスケーラビリティを示しています。
NVIDIA BlackwellおよびHopper GPU搭載のOCI Supercluster
最大131,072のGPU、8倍のスケーラビリティ
ネットワーク・ファブリックの革新により、OCI Superclusterは最大131,072のNVIDIA B200 GPU、100,000を超えるBlackwell GPUを搭載したNVIDIA Grace Blackwell Superchips、および65,536 NVIDIA H200 GPUまで拡張できます。
あらゆるニーズに対応するOCIのAIインフラストラクチャ
推論や微調整の実行、生成AI用の大規模スケールアウト・モデルのトレーニングなど、OCIはお客様のAIニーズに合わせて、超広帯域ネットワークと高いパフォーマンス・ストレージを実装した業界をリードするベアメタルや仮想マシンのGPUクラスタ・オプションを提供します。
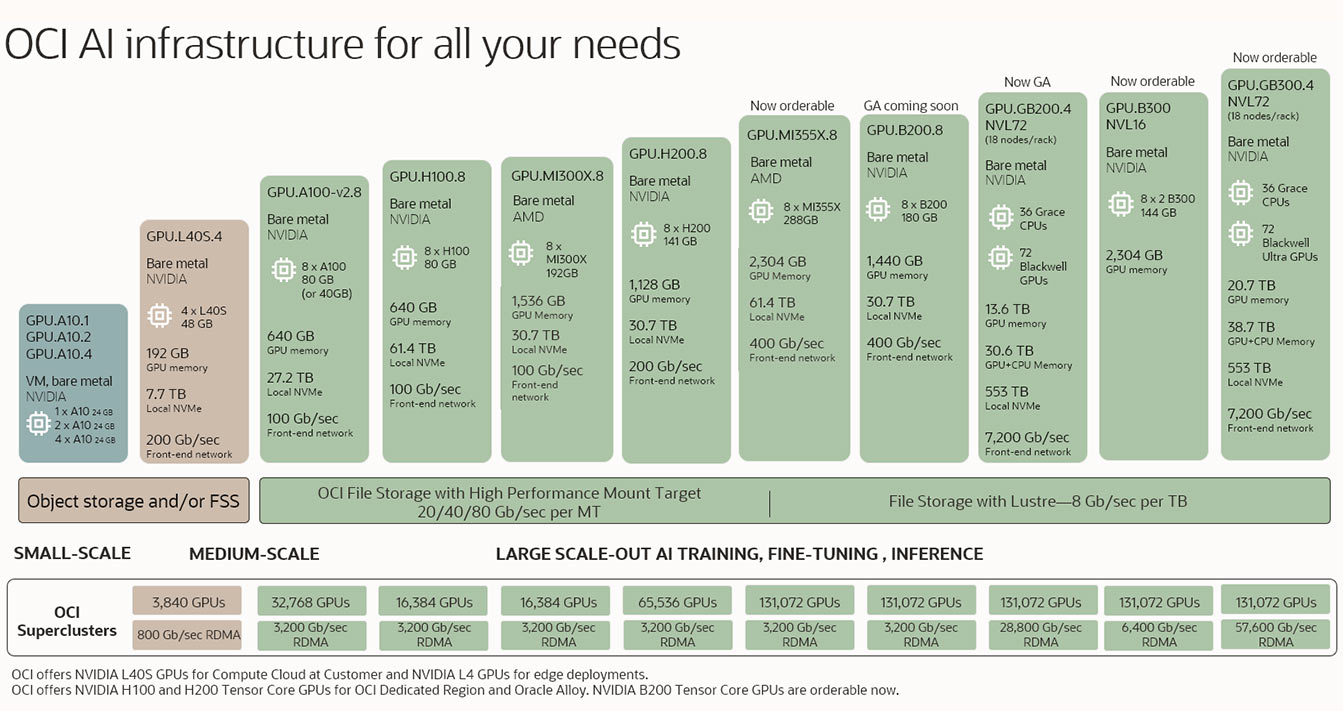 画像は、左下から始まり、最小構成から徐々に中規模、大規模構成へと進むAIインフラストラクチャの複数の製品を示しています。最小構成は仮想マシンにわずか1つのGPUを搭載したもので、最大構成はRDMAクラスタに10万以上のGPUを搭載したものです。
画像は、左下から始まり、最小構成から徐々に中規模、大規模構成へと進むAIインフラストラクチャの複数の製品を示しています。最小構成は仮想マシンにわずか1つのGPUを搭載したもので、最大構成はRDMAクラスタに10万以上のGPUを搭載したものです。 AMD MI355X GPUを搭載したOCI Computeの一般提供を発表
大規模AIトレーニングのためのOCIクラスタの詳細
NVIDIA BlackwellとHopperを使用した大規模なスケールアウト・クラスタ
スーパーチャージド・コンピュート
- ハイパーバイザーのオーバーヘッドを必要としないベアメタル・インスタンス
- NVIDIA Blackwell (GB200 NVL72、HGX B200)、
Hopper (H200、H100)、および旧世代のGPUによる高速化
- AMD MI300X GPUを使用するオプション
- 組み込みのハードウェア・アクセラレーション用データ処理ユニット(DPU)
大容量および高スループット・ストレージ
• ローカル・ストレージ: 最大61.44TBのNVMe SSD容量
• ファイル・ストレージ: Lustreおよび高パフォーマンス・マウント・ターゲットを備えたOracle管理ファイル・ストレージ。
• ブロック・ストレージ: パフォーマンスSLAによるバランスの取れた高パフォーマンスおよび超高パフォーマンス・ボリューム
• オブジェクト・ストレージ: 個別のストレージ・クラス層、バケット・レプリケーションおよび大容量制限
超高速ネットワーク
• カスタム設計のRDMA over Converged Ethernetプロトコル(RoCE v2)
• クラスタ・ネットワーキングのレイテンシ
が最大3,200 Gb/秒
• フロントエンド・ネットワーク帯域帯域幅は最大400 Gb/秒
OCI Supercluster向けコンピュート
NVIDIA GB200 NVL72、NVIDIA B200、NVIDIA H200、AMD MI300X、NVIDIA L40S、NVIDIA H100、およびNVIDIA A100 GPUを実装したOCIベアメタル・インスタンスにより、ディープラーニング、対話型AI、生成AIなどのユースケース用に大規模AIモデルを実行できます。
OCI Superclusterでは、100,000を超えるGB200 Superchips、131,072 B200 GPU、65,536 H200 GPU、32,768 A100 GPU、16,384 H100 GPU、16,384 MI300X GPU、およびクラスタ当たり3,840 L40S GPUまでスケールアップが可能です。

拡大+
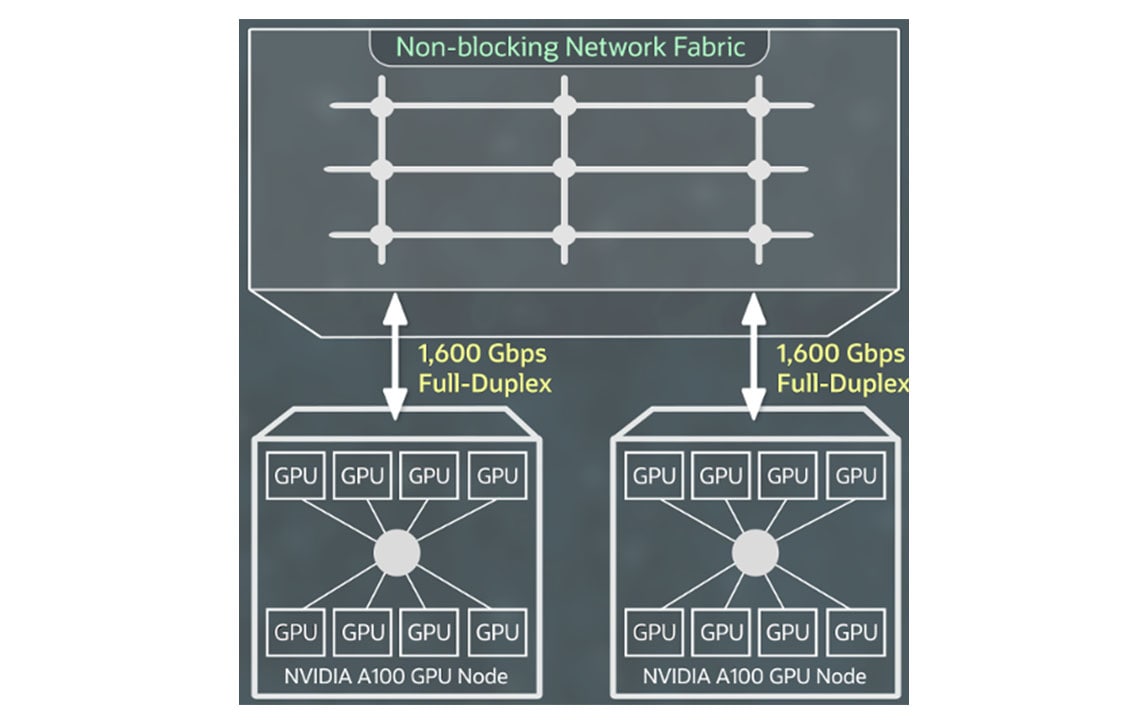
スーパークラスタ向けネットワーキング
RDMA over Converged Ethernet v2を実装したNVIDIA ConnectXネットワーク・インターフェイス・カードによる高速RDMAクラスタ・ネットワーキングにより、オンプレミスと同じ超低レイテンシ・ネットワーキングとアプリケーションのスケーラビリティを備えたGPUインスタンスの大規模クラスタを作成できます。
RDMA機能、ブロック・ストレージ、ネットワーク帯域幅に追加料金を支払う必要はなく、最初の10TBのイグレスは無料です。
拡大+
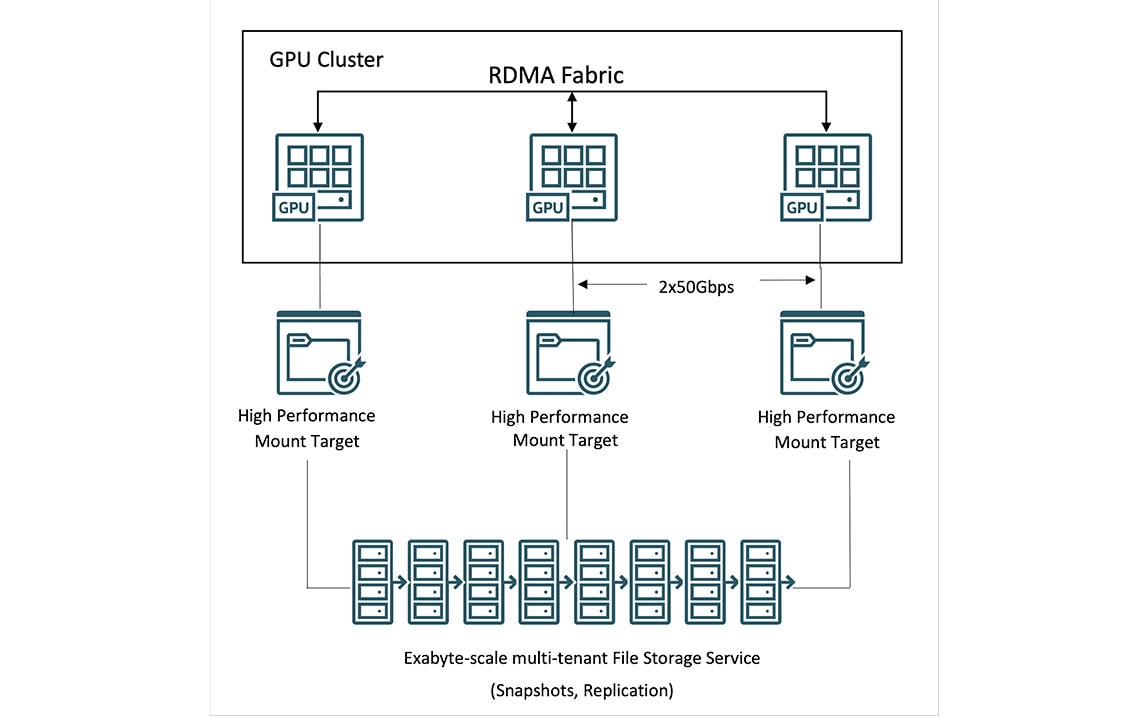
OCI Supercluster向けストレージ
お客様はOCI Superclusterを介して、ペタバイト・スケール・コンピューティング向けのローカル・ブロック・オブジェクト・ファイルストレージにアクセスが可能です。主要なクラウド・プロバイダーの中で、OCIは最高容量の高いパフォーマンス・ローカルNVMeストレージを提供しており、トレーニング実行中のチェックポイントをより頻繁に行うことで、障害からの復旧をより迅速に行うことができます。
膨大なデータセットに対して、OCIはLustreとマウント・ターゲットによる高パフォーマンスのファイル・ストレージを提供します。BeeGFS、GlusterFS、WEKAを含むHPCファイルシステムは、パフォーマンスを損なうことなく大規模なAIトレーニングに利用できます。

Zettascale OCIスーパークラスタ
OCIのトップ・アーキテクトが、クラスタネットワークがスケーラブルな生成AIを実現する方法をご紹介します。数個のGPUから131,000以上のNVIDIA Blackwell GPUを搭載したゼータスケールのOCIスーパークラスタまで、クラスタネットワークは高速、低レイテンシ、耐障害性の高いネットワークを提供し、AIジャーニーを実現します。
Seekr、エンタープライズおよび政府の顧客に信頼できるAIをグローバルに提供するためにOracle Cloud Infrastructureを選択
Oracle PR、Abel Habtegeorgis信頼できるAIの提供に注力する人工知能企業Seekrは、Oracle Cloud Infrastructure(OCI)と複数年契約を締結し、エンタープライズAIの導入を迅速に加速し、共同市場参入戦略を実行します。
全文を読む注目のブログ
- 2025年3月26日 パブリック・クラウド、オンプレミス・クラウド、サービスプロバイダー・クラウド向けにNVIDIA Blackwellを搭載した新しいAIインフラストラクチャ機能を発表
- 2025年3月17日 AIイノベーションの推進: OCI上のNVIDIA AI EnterpriseとNVIDIA NIM
- 2025年3月17日 オラクルとNVIDIA、ソブリンAIをどこでも提供
- 2025年3月11日 ゼロからAIヒーローへ- OCIにAIワークロードを迅速に導入
一般的なAIインフラストラクチャのユースケース
GPU、RDMAクラスタ・ネットワーク、OCI Data Scienceを実装したOCIベアメタル・インスタンスでAIモデルをトレーニングします。

毎日行われる何十億という金融取引を保護するためには、大量の履歴顧客データを分析できる強化されたAIツールが必要となります。NVIDIA GPUを実装したOCI Compute上で実行されるAIモデルは、OCI Data Scienceやその他のオープン・ソース・モデルなどのモデル管理ツールとともに、金融機関による不正行為の軽減を支援します。

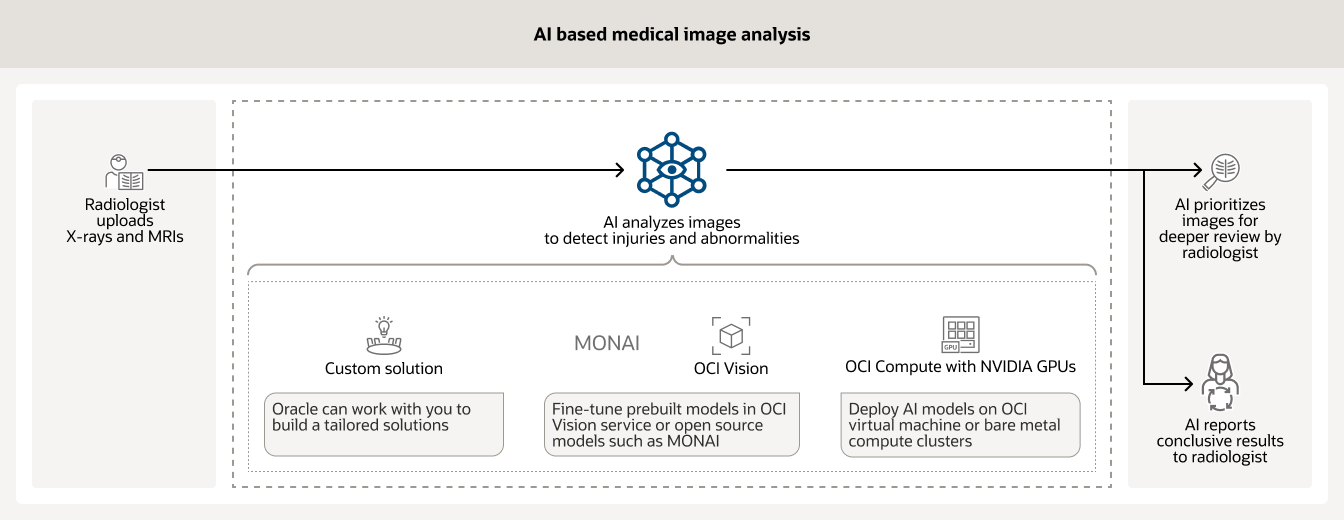
AIは、病院内のさまざまな種類の医療画像(X線やMRIなど)の解析によく利用されています。トレーニングしたモデルを使用することで、放射線科医による早急なレビューが必要な症例の優先度設定を支援でき、その他の症例については決定的な結果を報告することができます。
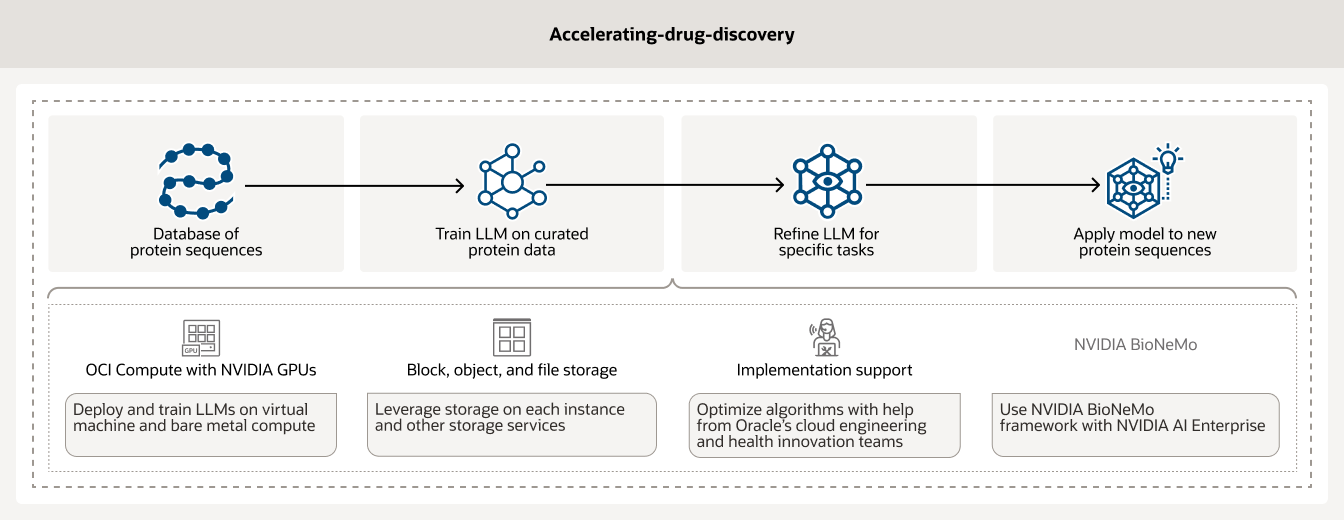
創薬には長い年月と数百万ドルの費用がかかる、時間のかかる高コストなプロセスです。AIインフラストラクチャと分析を活用することで、研究者は創薬を加速することができます。さらに、NVIDIA GPUを実装したOCI ComputeとBioNeMoなどのAIワークフロー管理ツールにより、お客様はデータのキュレーションと前処理を行うことができます。
AI infrastructureのお客様事例















OCI AIインフラストラクチャの利用開始
-
次のような質問に回答できます。
- Oracle Cloudを使い始めるには、どうすればよいですか。
- OCIで実行可能なAIワークロードを教えてください。
- OCIで提供されているAIサービスを教えてください。
今すぐAIの活用方法を見る
ビジネス向けの生成AIソリューションにより、生産性の新時代が幕を開けようとしています。オラクルが、テクノロジー・スタック全体にわたるAIの活用でお客様を支援する方法をご覧ください。
-
Oracle AIで実現できること
- OCIにおけるLLMのファインチューニング
- 請求処理の自動化
- RAGによるチャットボットの作成
- 生成AIによるWebコンテンツの要約
- その他
その他のリソース
RDMAクラスタ・ネットワーキング、GPUインスタンス、ベアメタル・サーバーなどの詳細をご覧ください。
OCIでのコスト削減を試算してみましょう
Oracle Cloudの価格は、わかりやすく、世界中で一貫性のある低価格であり、さまざまなお客様事例をサポートしています。コストを試算するには、コスト見積ツールをチェックし、ニーズに応じて、サービスを設定します。
違いを体験してください
- 1/4のアウトバウンド帯域幅コスト
- コンピューティングのコストパフォーマンスが3倍向上
- すべてのリージョンで同じ低価格
- 長期のコミットメントなしの低価格