Qu'est-ce qu'un data lakehouse ?
Mike Chen | Responsable de la stratégie du contenu | 1 mars 2022

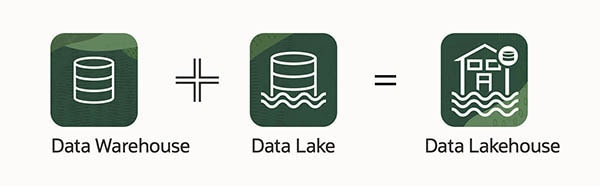
Un data lakehouse peut être défini comme une plateforme de données moderne construite à partir d'une combinaison d'un data lake et d'un data warehouse. Plus précisément, un data lakehouse prend le stockage flexible de données non structurées à partir d'un lac de données et les fonctionnalités et outils de gestion des entrepôts de données, puis les implémente stratégiquement ensemble en tant que système plus vaste. Cette intégration de deux outils uniques apporte le meilleur des deux mondes aux utilisateurs. Pour décomposer encore plus un data lakehouse, il est important de bien comprendre la définition des deux termes d'origine.
Data Lakehouse vs. Data Lake vs. Data Warehouse
Lorsque nous parlons d'un data lakehouse, nous faisons référence à l'utilisation combinée des plateformes de référentiel de données actuelles.
- Lac de données (le "lac" dans le lakehouse) : un lac de données est un référentiel de stockage à faible coût principalement utilisé par les data scientists, mais également par les analystes métier, les chefs de produit et d'autres types d'utilisateurs finaux. C'est un concept de big data. Les données brutes non structurées provenant de diverses sources organisationnelles entrent dans le lac, souvent pour la préparation avant le chargement dans un entrepôt de données et la création d'ensembles de données.
- Data warehouse : un entrepôt de données est un type différent de référentiel de stockage d'un lac de données dans la mesure où un entrepôt de données stocke des données traitées et structurées, organisées à des fins spécifiques et stockées dans un format spécifié. Ces données sont généralement interrogées par les utilisateurs professionnels qui utilisent les données préparées dans des outils d'analyse pour le reporting et les projections. Un data warehouse inclut généralement des fonctionnalités de gestion des données telles que le nettoyage des données et l'extraction, le chargement et la transformation (ETL).
Comment un data lakehouse combine-t-il ces deux idées ? En général, un data lakehouse supprime les cloisons entre un lac de données et un entrepôt de données. Cela signifie que les données peuvent être facilement déplacées entre le stockage à faible coût et flexible d'un lac de données vers un entrepôt de données et vice versa, ce qui permet d'accéder facilement aux outils de gestion d'un entrepôt de données pour l'implémentation du schéma et de la gouvernance, souvent alimentés par le machine learning et l'intelligence artificielle pour le nettoyage des données. Le résultat crée un référentiel de données qui intègre la collecte abordable et non structurée de lacs de données et la préparation robuste d'un entrepôt de données. En fournissant l'espace nécessaire à la collecte à partir de sources de données organisées tout en utilisant des outils et des fonctionnalités qui préparent les données pour une utilisation professionnelle, un data lakehouse accélère les processus. D'une certaine manière, les data lakehouses sont des data warehouses, d'origine conceptuelle au début du 1980s, qui ont été relancés pour notre monde moderne axé sur les données.
Caractéristiques d'un data lakehouse
Avec une compréhension du concept général d'un data lakehouse, examinons un peu plus en détail les éléments spécifiques impliqués. Un data lakehouse offre de nombreux éléments familiers des concepts historiques de data lake et de data warehouse, mais d'une manière qui les fusionne en quelque chose de nouveau et de plus efficace pour le monde numérique d'aujourd'hui.
Caractéristiques de Data Management
Un data warehouse offre généralement des fonctionnalités de gestion des données telles que le nettoyage des données, ETL et l'application des schémas. Elles sont intégrées dans un data lakehouse afin de préparer rapidement les données, ce qui permet aux données provenant de sources sélectionnées de fonctionner ensemble et d'être préparées pour de nouveaux outils d'analyse et de business intelligence (BI).
Formats de stockage ouverts
L'utilisation de formats de stockage ouverts et standardisés signifie que les données provenant de sources de données variées ont une longueur d'avance en ce qui concerne leur capacité à fonctionner ensemble et être prêtes pour l'analyse ou le reporting.
Stockage flexible
La possibilité de séparer les ressources de calcul des ressources de stockage facilite le redimensionnement du stockage si nécessaire.
Prise en charge de Streaming
De nombreuses sources de données utilisent la diffusion en continu en temps réel directement à partir des appareils. Un data lakehouse est conçu pour mieux prendre en charge ce type d'ingestion en temps réel par rapport à un data warehouse standard. À mesure que le monde intègre davantage les appareils Internet of Things, le support en temps réel devient de plus en plus important.
Divers workloads
Etant donné qu'un data lakehouse intègre les fonctionnalités d'un data warehouse et d'un lac de données, il s'agit d'une solution idéale pour un certain nombre de workloads différents. Des rapports commerciaux aux équipes de data science en passant par les outils d'analyse, les qualités inhérentes à un data lakehouse peuvent prendre en charge différents workloads au sein d'une entreprise.
Avantages d'un data lakehouse : une plateforme de données innovante
En créant un data lakehouse, les entreprises peuvent rationaliser leur processus global de gestion des données avec une plateforme de données unifiée. Un data lakehouse peut remplacer des solutions individuelles en cassant les cloisons qui se dressent entre plusieurs référentiels. Cette intégration crée un processus de bout en bout beaucoup plus efficace que les sources de données organisées. Cela crée plusieurs avantages.
- Moins d'administration : à l'aide d'un data lakehouse, toutes les sources qui y sont connectées peuvent avoir leurs données accessibles et consolidées pour utilisation, plutôt que de les extraire des données brutes et de se préparer à travailler dans un data warehouse.
- Meilleure gouvernance des données : les data lakehouses simplifient et améliorent la gouvernance en consolidant les ressources et les sources de données et sont construits avec un schéma ouvert standardisé, qui permet un meilleur contrôle de la sécurité, des mesures, de l'accès basé sur les rôles et d'autres éléments de gestion cruciaux.
- Normes simplifiées : les entrepôts de données proviennent des années 1980, où la connectivité était extrêmement limitée, ce qui signifie que des normes de schéma localisées ont souvent été créées au sein des entreprises, même des services. Aujourd'hui, des normes de schémas ouvertes existent pour de nombreux types de données, et les data lakehouses en tirent parti en ingérant plusieurs sources de données avec des schémas standardisés qui se recoupent pour simplifier les processus.
- Augmentation de la rentabilité : les data lakehouses sont construits avec une infrastructure qui sépare le calcul et le stockage, ce qui permet d'ajouter facilement du stockage sans avoir à augmenter la puissance de calcul. Cela permet une mise à l'échelle rentable grâce à l'utilisation simple du stockage de données à faible coût.
Alors que certaines entreprises vont construire un data lakehouse, d'autres vont acheter un service cloud de data lakehouse.
Témoignages clients : Data Lakehouse

Experian a amélioré ses performances de 40 % et réduit ses coûts de 60 % lorsqu'il a migré des workloads de données critiques d'autres clouds vers un data lakehouse sur OCI, accélérant le traitement des données et l'innovation produit tout en élargissant les opportunités de crédit dans le monde entier.
Generali Group est une compagnie d'assurance italienne avec l'une des plus grandes bases de clients au monde. Generali disposait de nombreuses sources de données, provenant à la fois d'Oracle Cloud HCM et d'autres sources locales et régionales. Leur processus de décision RH et l'implication des employés se heuraient à des obstacles, et l'entreprise a cherché une solution pour améliorer l'efficacité. L'intégration d'Oracle Autonomous Data Warehouse aux sources de données de Generali a permi de supprimer les silos et de créer une ressource unique pour toutes les analyses RH. Cela a amélioré l'efficacité et la productivité du personnel RH, lui permettant de se concentrer sur des activités à valeur ajoutée plutôt que sur l'attrition de la génération de rapports.

L'un des principaux fournisseurs de covoiturage au monde, Lyft s'occupait de 30 systèmes financiers cloisonnés différents. Cette séparation a entravé la croissance de l'entreprise et ralenti les processus. En intégrant Oracle Cloud ERP et Oracle Cloud EPM à Oracle Autonomous Data Warehouse, Lyft a pu consolider ses finances, ses opérations et ses analyses sur un seul système. Cela a permis de réduire de 50 % le temps nécessaire à la clôture de ses comptes, avec la possibilité d'une rationalisation encore plus poussée de ses processus. Cela lui a également permis d'économiser sur les coûts en réduisant les heures d'inactivité.

Agroscout est un développeur logiciel qui aide les agriculteurs à maximiser les cultures saines et sûres. Pour augmenter la production alimentaire, Agroscout a utilisé un réseau de drones pour enquêter sur les cultures à la recherche d'insectes ou des maladies. L'organisation avait besoin d'un moyen efficace à la fois de consolider les données et de les traiter pour identifier les signes de danger pour les cultures. Grâce à Oracle Object Storage Data Lake, les drones ont directement téléchargé des cultures. Des modèles de machine learning ont été créés avec OCI Data Science pour traiter les images. Le résultat a été un processus considérablement amélioré qui a permis une réponse rapide à l'augmentation de la production alimentaire.
Découvrez comment OCI constitue le meilleur endroit pour construire un Lakehouse
Chaque jour qui passe, de plus en plus de sources de données envoient de plus en plus de volumes de données dans le monde entier. Pour toute entreprise, cette combinaison de données structurées et non structurées reste un défi. Les data lakehouses relient, corrélent et analysent ces différentes résultats en un seul système gérable.